Vespa provides a tensor data model and computation engine to support advanced computations over data.
This guide explains the tensor support in Vespa. See also the tensor reference,
and our published paper
(pdf).
Tensor concepts
A tensor in Vespa is a data structure which generalizes scalars, vectors and matrices to any number of dimensions:
A scalar is a tensor of rank 0
A vector is a tensor of rank 1
A matrix is a tensor of rank 2
...
Tensors consist of a set of scalar valued cells, with each cell having a unique address.
A cell's address is specified by its index or label in all the dimensions of that tensor.
The number of dimensions in a tensor is the rank of the tensor.
Each dimension can be either mapped or indexed.
Mapped dimensions are sparse and allow any label (string identifier) designating their address,
while indexed dimensions use dense numeric indices starting at 0.
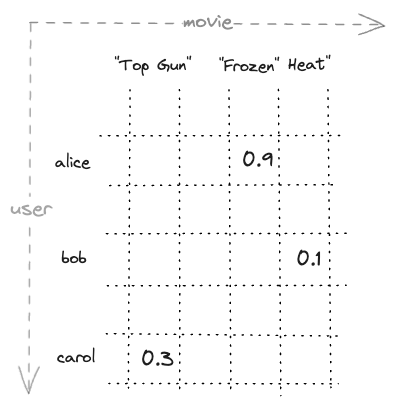
has two dimensions named user and movie, and has three cells with defined values:
A tensor has a type, which consists of a set of dimension names, dimension types, and
a tensor cell value type.
The dimension name can be anything.
This defines a 2-dimensional mapped tensor (sparse 2D matrix) of floats as illustrated above:
tensor<float>(user{},movie{})
This is a 2-dimensional indexed tensor (a 2D 1280x720 matrix). For example, used to represent an image:
tensor<int8>(x[1280],y[720])
This is a 3-dimensional indexed tensor. For example, used to represent spatial data:
tensor<float>(x[256], y[256], z[128])
This is a mixed tensor combining a mapped dimension and an indexed dimension. For example, used
to represent word2vec:
Vespa uses the tensor type information to optimize tensor expression execution plans at configuration time.
Tensor document fields
Document fields in schemas can be of any tensor type:
schema product {
document product {
field title type string {
indexing: summary | index
}
field price type int {
indexing: summary | attribute
}
field popularity type float {
indexing: summary | attribute
}
field sales_score type tensor<float>(category{}) {
indexing: summary | attribute
}
field embedding type tensor<float>(x[4]) {
indexing: summary | attribute | index
attribute {
distance-metric: dotproduct
}
}
}
}
The above schema exemplifies a product with two tensor fields.
The sales_score tensor field represents
how popular a product is per unique category. This information could be used when
ranking products for a user query. The embedding
tensor field represents an embedding vector representation of the product.
sales_score is a mapped tensor with a single mapped dimension category.
Mapped dimensions are sparse and allow any label (string identifier) designating their address.
embedding is an indexed tensor. Indexed dimensions use dense numeric indices starting at 0.
To perform computations over a document tensor field in ranking,
the field must be defined with attribute.
Tensors with the following types can be indexed with HNSW and searched
efficiently using the nearestNeighbor query operator:
One indexed dimension - single vector per tensor field
One mapped and one indexed dimension - multiple vectors per tensor field
An example product document in Vespa JSON format.
This example uses the product category string as the mapped label key.
The embedding tensor stores and indexes (HNSW) a
dense embedding.
{"put":"id:shopping:product::B0BFW5SXX2","fields":{"title":"Keyboard Case for iPad Pro 12.9 inch","price":29,"popularity":0.8,"sales_score":{"Tablet Keyboard Cases":8.0,"Keyboards":2.0,"Personal Computers":0.1},"embedding":[1,2,3,4]}}
The JSON feed format example above uses short value form.
Tensor fields can be represented using different
JSON format verbosity.
You would typically re-calculate the per category sales scores outside Vespa and update them continuously
using partial updates to avoid re-feeding or re-indexing of other fields.
Querying with tensors
Query input tensors must be defined in the schema rank-profile using
inputs:
The above defines two query input tensors that we can reference in ranking expressions.
With the tensor query name and tensor type defined, you can:
Add it to the query in a Searcher using the
Tensor class
and setting it by Query.getRanking().getFeatures.put("query(q_embedding)", myTensorInstance), or
Pass it in the request, using an HTTP parameter like input.query(q_embedding) and
passing a tensor value.
vespa query 'yql=select * from product where {targetHits:1}nearestNeighbor(embedding,q_embedding)'\'input.query(q_embedding)=[1,2,3,4]'\'input.query(q_category)={"Tablet Keyboard Cases":0.8, "Keyboards":0.3}'\'ranking=product_ranking'
This query request example assumes that the user query has been mapped (classified) to be related to the
Tablet Keyboard Cases and Keyboards categories. Similarly, the user query has been mapped to
a dense vector representation (query(q_embedding) and is used as
input to the nearestNeighbor
query operator, expressed with the YQL query language.
The Vespa CLI uses HTTP GET and you can use the -v flag to see the curl GET equivalent. For
POST query requests using JSON, the equivalent JSON is:
{"yql":"select * from product where {targetHits:1}nearestNeighbor(embedding,q_embedding)","input":{"query(q_embedding)":[1,2,3,4],"query(q_category)":{"Tablet Keyboard Cases":0.8,"Keyboards":0.3}},"ranking":"product_ranking"}
If the input query tensor used for the nearestNeighbor
operator is not defined in the schema rank-profile, the request will fail:
"Expected 'query(q_embedding)' to be a tensor, but it is the string '[1,2,3,4]'"
Ranking with tensors
Tensors can be used in making inference computations over documents that are matched by a query.
These computations are expressed with ranking expressions in
schema rank profiles. We can use this support
to rank products by both the dense embedding dot product similarity and the category sales score.
The above profile uses a combination of two dot product calculations in the first phase expression.
The first-phase expression is invoked for all documents that are retrieved
by the YQL query language.
The p_sales_score function calculates the sparse tensor dotproduct between the query(q_category) and attribute(sales_score) tensor.
The p_embedding_score calculates the dense tensor dotproduct between the query(q_embedding) and attribute(embedding) tensors.
The function uses the closeness(dimension,name)rank-feature
which is calculated by the nearestNeighbor query operator. Alternatively, if we don't
use the nearestNeighbor operator in the query request, we could use sparse tensor dotproduct:
function p_embedding_score() {
expression: sum(query(q_embedding) * attribute(embedding))
}
The full list of tensor functions are listed in the
ranking expression reference.
Using match-features, developers
can debug, or log function outputs in the search result.
"matchfeatures": {
"p_embedding_score": 30.0,
"p_sales_score": 8.0,
},
"documentid": "id:shopping:product::B0BFW5SXX2",
"title": "Keyboard Case for iPad Pro 12.9 inch"
Creating tensors from document fields
If you need to make tensor computations from non-tensor single-valued attributes, arrays, weighted sets,
or array<struct> fields, you can convert them in a ranking expression:
Creating an indexed tensor where the values are lifted from single-value
attributes (price and popularity) using the tensor generate function:
function to_indexed_tensor() {
expression: tensor(x[2]):[attribute(price),attribute(popularity)]
}
Creating a mapped tensor where the values are lifted from single-value
attributes using the tensor generate function:
function to_mapped_tensor() {
expression: tensor(x{}):{key1:attribute(price),key2:attribute(popularity)}
}
Creating a mapped tensor where the label(s) are lifted from a string array or
single-value attribute can be done with the
document featuretensorFromLabels.
Creating a mapped tensor where the labels and values are lifted from a weighted set can be done with the
document featuretensorFromWeightedSet.
Creating a mapped tensor where labels and values are lifted from an
array<struct> attribute can be done with the
document featuretensorFromStructs.
Converting non-tensor fields to tensors at query runtime has a performance penalty that is linear with the number of elements
in the array, weighted set, or struct array. Prefer using native tensor fields instead.
The benefit of converting non-tensor fields is that non-tensor fields like
int, float, weightedset, or array<struct> can be efficiently queried.
Only specific tensor types can be searched efficiently using the
nearestNeighbor query operator.
Constant tensors
In addition to document tensors and query tensors,
constant tensors
can be put in the application package.
This is useful for adding machine learned models. Example:
This defines a new tensor with the type as defined and the
contents distributed with the application package in the file
constants/constant_tensor_file.json. The format of this file is the
constant tensor JSON format:
Note that the rank profile inherit the inputs we defined in the product_ranking profile.
With the example data used, the first-phase expression returns the 16.0 since:
Tensors in Vespa cannot have strings as values, since the mathematical tensor functions
would be undefined for such "tensors". However, you can still represent sets of strings in tensors
by using the strings as keys in a mapped tensor dimensions, using e.g 1.0 as values.
This allows you to perform set operations on strings and similar without making those tensors
incompatible with other tensors and with normal tensor operations.