-
Applications and components
- Developer guide
- IDE support
- Deployment
- .vespaignore files
- Containers
- Components
- Searchers
- Document processors
- Request handlers
- Result renderers
- Dependency injection
- Configuring components
- Chaining
- Inspecting structured data in a Searcher
- Developing web services
- Unit testing
- System testing
- The config system
- Request-response processing
- Bundles
- Using ZooKeeper
- Http servers and filters
- Using pluggable frameworks
- Java config API
-
Querying
- The query api
- The YQL query language
- Grouping and aggregation
- Federation
- Query profiles
- An intro to vector search
- Nearest neighbor search
- Approximate nearest neighbor search
- Nearest neighbor search guide
- Text matching
- Searching multivalue fields
- Geo search
- Document summaries
- Result diversity
- Page templates
-
Ranking and inference
- Ranking introduction
- Ranking expressions and features
- Multivalue query operators
- Tensor user guide
- Tensor examples
- Phased ranking
- Using TensorFlow models
- Using ONNX models
- Using XGBoost models
- Using LightGBM models
- Wand: Accelerated OR search
- The BM25 rank feature
- The nativeRank rank feature
- Cross-encoder transformer ranking
- Searcher re-ranking
- Significance model
- Stateless model evaluation
-
Linguistics and text processing
-
Content and elasticity
-
Performance
- Performance overview
- Practical performance guide
- Serving sizing guide
- Feed sizing guide
- Node resources
- Sizing examples
- Topology and resizing
- Streaming search
- Benchmarking
- Benchmarking using Vespa Cloud
- Memory visualizer
- Profiling
- Container tuning
- Rate-limiting queries
- Graceful degradation
- Caches
- HTTP performance testing
- HTTP/2
- Feature tuning
- Valgrind
-
Operations
- Environments
- Zones
- Production deployment
- Deployment variants
- Automated deployments
- Autoscaling
-
Enclave: Bring your own cloud
- Reindexing
- Data management and backup
- Cloning applications and data
- Monitoring
- Metrics
- Notifications
- Deployment patterns
- Private endpoints
- Endpoint routing
- Access logging
-
Artifact archive
- Deleting applications
-
Self-managed
- Admin procedures
- Multinode Systems
- Files, Processes, Ports, Environment
- Node Setup
- Using Kubernetes
- Build and install
- Monitoring
- Content node recovery
- Configuration Servers
- Live Vespa upgrade procedure
- Config Sentinel
- Config Proxy
- Docker Containers
- Docker Containers GPU setup
- CPU Support
- Service Location Broker
- Change from attribute to index procedure
- Container
- Vespa Support CLI
-
Modules
-
Reference
-
Applications and components
-
Schemas and documents
-
Reading and writing
-
Operations
- Health checks
- Log files
- Tools
-
Self-managed
-
Security
-
Release notes
This guide goes through the following aspects of node resource configuration:
- Independent configuration of resource dimensions
- Using automated resource suggestions
- Deployment automation for rapid optimization cycles
- Automated instance type migration for optimal performance over time
Independent resource dimensions
In Vespa Cloud, a node's resources is configured like:
<nodes count="8">
<resources vcpu="4" memory="16Gb" disk="300Gb"/>
</nodes>
With this, you specify the dimensions independently. E.g., one can double the CPU, keeping all other dimensions constant.
This is important when tuning for the optimal price/performance point, as the pieces of an application has different sweet spots. For example, the product search cluster of an application can be more CPU bound than product recommendations; the latter might need relatively more memory.
Optimizing for cost/performance is therefore easy. Simplified, applications can be CPU, disk, or memory bound. A general rule of thumb is to be bound by the most expensive component, often CPU. Refer to the node resource reference for all dimensions.
Resource suggestions
Applications change over time:
- Data size growth
- Query rate growth
- Write rate growth
- Schema changes, like new fields or binarized embeddings
Finding the optimal node configuration is an iterative process. It is simplified by using the Resource Suggestions view in the Vespa Console:
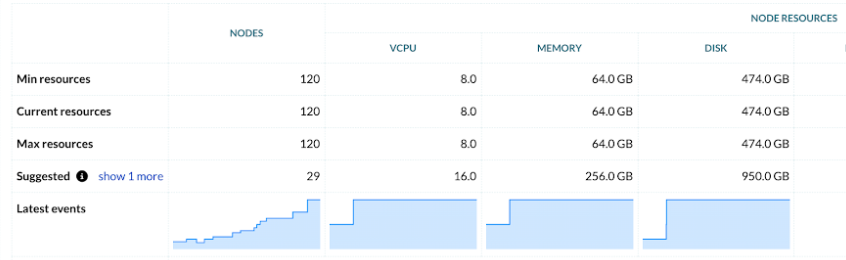
Vespa Cloud tracks usage over time and suggests node configuration and topology changes based on last week's load. In the example above, observe a suggestion that doubles the memory relative to CPU.
This simplifies what to configure, and one can roll out isolated changes while observing latency and other business metrics like relevance quality.
Automated resource configuration deployment
Resource configuration is part of the application package. To change a cluster's resources, deploy the new version of the application package to Vespa Cloud and wait for the changes to apply:
- Changes to stateless Vespa Container clusters are almost instant, dependent on the cloud provider's provisioning latency.
- Changes to stateful Vespa Content clusters (where the document indices are stored) take more time,
as data is redistributed for uniform load:
- Changing the node
countwill modify the existing cluster. - Changing the
resourcesconfiguration will set up a parallel cluster and migrate data to it. This is generally slower than changing the node count, as more data moves.
- Changing the node
Making changes to the resource specifications is hence fully automated. The quickest way to the sweet spot is to initially deploy with enough capacity and do daily re-tuning to cut cost.
Vespa Cloud provides performance dashboards with the relevant metrics in this phase:
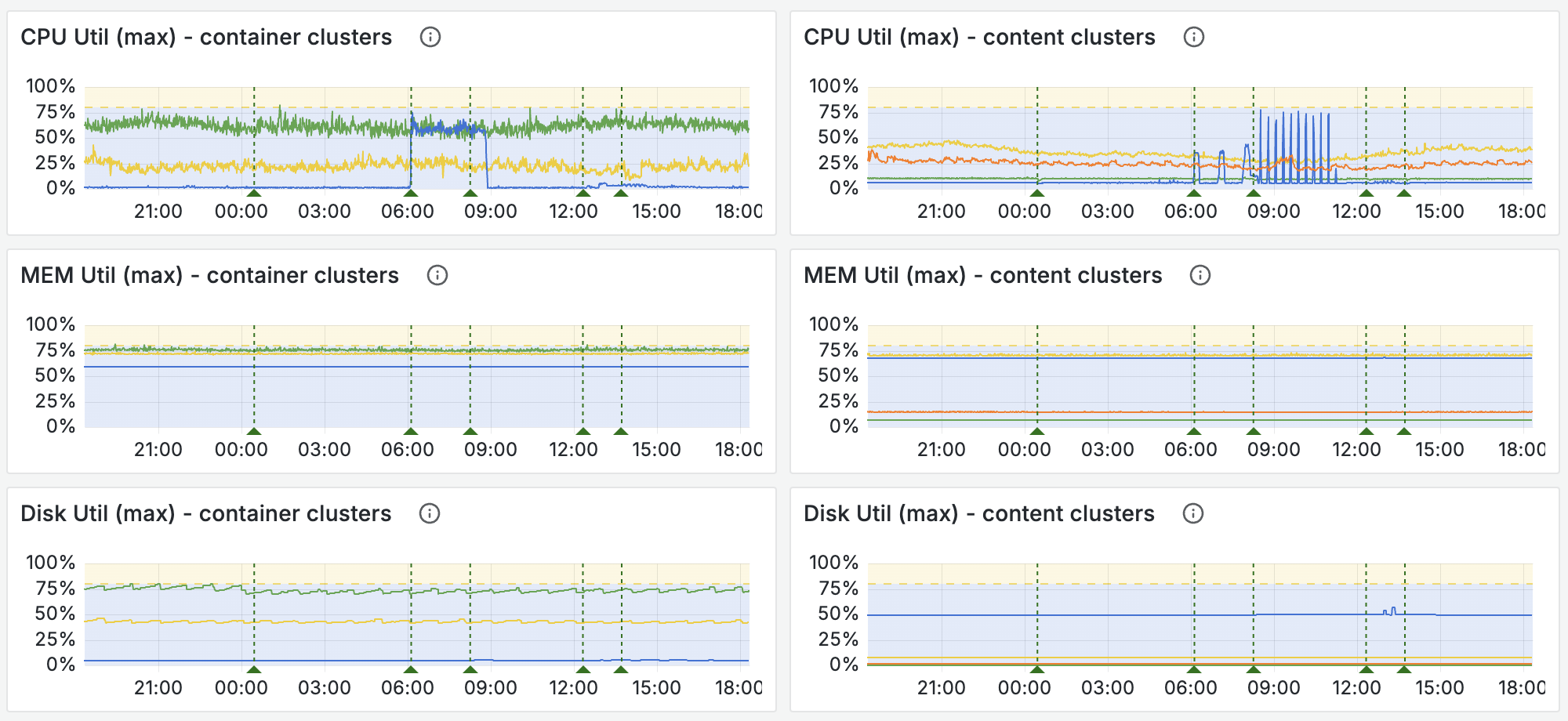
Eventually, the application has its optimal price/performance characteristics, without lengthy benchmarking activities.
Automated instance type migration
Resource configurations map to the cloud provider's real resources, like AWS EC2 compute instances. The instance inventory develops over time, like:
- r7g_4xlarge (Graviton3)
- r8g_4xlarge (Graviton4)
Both have 16 vCPU and 128G RAM, but r8g_4xlarge is of a newer generation, and has presumably higher performance: "R8g instances deliver around 30% higher performance over R7g instances, …"
resources configuration is general and independent of instance types,
Vespa Cloud will automatically migrate load to more cost-effective compute instances over time.
This means, Vespa Cloud applications will migrate to more recent instance types of the same configuration, with zero manual interventions. This keeps the total cost in check, and performance tracking advances in hardware.
Find a list of supported instance types at AWS, GCP, and Azure instance types.