The nativeRank text match score is a reasonably good text feature score which is computed at an acceptable performance by Vespa. It computes a normalized rank score which tries to capture how well query terms matched the set of searched index fields.
The nativeRank feature is computed as a linear combination of three other matching features: nativeFieldMatch, nativeProximity and nativeAttributeMatch, see the nativeRank reference for details.
Ranking signals that might be useful, like freshness (the age of the document compared to the time of the query) or any other document or query features, are not a part of the nativeRank calculation. These need to be added to the final ranking function depending on application specifics.
Weight, significance and connectedness
Modify the values of the match features from the query by sending weight, significance and connectedness with the query:
| Feature input | Description |
|---|---|
| Weight |
Set query term weight.
Example: The term weight is used in several text scoring features, including fieldMatch(name).weight and nativeRank. Note that the term weight is not applicable for all text scoring features, for example bm25 does not use the term weight. Configure static field weights in the schema. |
| Significance |
Significance is an indication of how rare a term is in the corpus of the language, used by a number of text matching rank features. This can be set explicitly for each term in the query, or by calling item.setSignificance() in a Searcher. With indexed search, default significance values are calculated automatically during indexing. However, unless the indexed corpus is representative of the word frequencies in the user's language, relevance can be improved by passing significances derived from a representative corpus. Relative significance is accessible in ranking through the fieldMatch(name).significance feature. Weight and significance are also averaged into fieldMatch(name).importance for convenience. Streaming search does not compute term significance, queries should pass this with the query terms. Read more. |
| Connectedness |
Signify the degree of connection between adjacent terms in the query - set query term connectivity to another term.
For example, the query Term connectedness is taken into account by fieldMatch(name).proximity, which is also an important contribution to fieldMatch(name). Connectedness is a normalized value which is 0.1 by default. It must be set by a custom Searcher, looking up connectivity information from somewhere - there is no query syntax for it. |
Using nativeRank
In this section we describe a blog search application that uses nativeRank as the core text matching rank feature, in combination with other signals that could be important for a blog search type of application:
schema blog {
document blog {
field title type string {
indexing: summary | index
}
field body type string {
indexing: summary | index
}
#The quality of the source in the range 0 - 1.0
field sourcequality type float {
indexing: summary | attribute
}
#seconds since epoch
field timestamp type long {
indexing: summary | attribute
}
field url type string {
indexing: summary
}
}
fieldset default {
fields: title, body
}
}
In addition to the core text match feature (nativeRank), we have a pre-calculated document feature which indicates the quality of the document represented by the field sourcequality of type float. The sourcequality field has the attribute property which is required to refer that field in a ranking expression: attribute(name). The sourcequality score could be calculated from a web map, or any other source and is outside the scope of this document.
We also know when the documented was published (timestamp) and this document attribute can be used to calculate the age of the document. To summarize, we have three main rank signals that we would like our blog ranking function to consist of:
- How well the query match the document text, where we use the nativeRank feature score.
- How fresh the document is, where we use the built-in age(name) feature to built our own feature score.
- The quality of the document, calculated outside of Vespa and referenced in a ranking expression by attribute(name).
Designing our own blog freshness ranking function
Vespa has several built in rank-features that we can use directly, or we can design our own as well if the built-in features doesn't meet our requirements. The built in freshness(name) rank-feature is linearly decreasing from 0 age (now) to the configured max age. Ideally we would like to have a different shape for our blog application, we define the following feature which has the characteristic we want:
function freshness() {
expression: exp(-1 * age(timestamp)/(3600*12))
}
Timestamp resolution is seconds, so we divide by 3600 to go to an hour resolution, and further we divide with 12 to control the slope of the freshness function. Below is a plot of two freshness functions with different slope numbers for comparison:
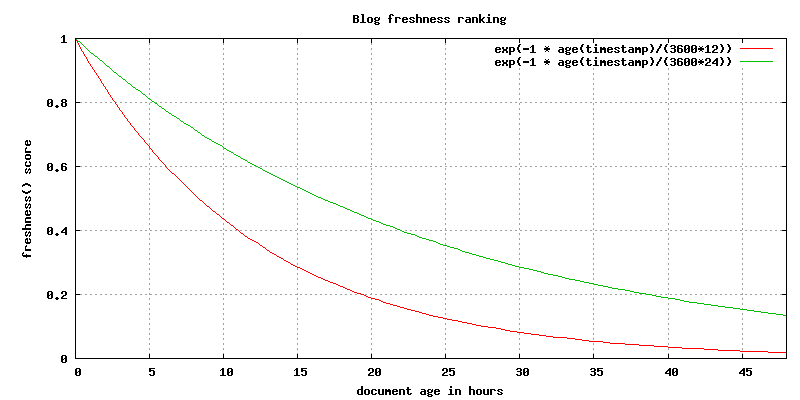
The beauty is that we can control and experiment with the freshness rank score given the document age. We can define any shape over any resolution that we think will fit the exact application requirements. In our case we would like to have a non-linear relationship between the age of the document and the freshness score. We achieve this with an exponential decreasing function (exp(-x)), where the sensitivity of x is higher when the document is really fresh compared to an old blog post (24 hours).
Putting our features together into a ranking expression
We now need to put our three main ranking signals together into one ranking expression. We would like to control the weight of each component at query time, so we can at query time do analysis to figure out if a certain signal should be weighted more than others. We chose to combine our three signals into a normalized weighted sum of the three signals. The shape of each of the three signals might be tuned individually as we have seen with design of our own freshness feature and nativeRank tuning. Below is the final blog rank-profile with all relevant settings (properties) and ranking expressions:
rank-profile blog inherits default {
weight title: 200
weight body: 100
rank-type body: about
rank-properties {
nativeFieldMatch.occurrenceCountTable.title: "linear(0,8000)"
}
# our freshness rank feature
function freshness() {
expression: exp(-1 * age(timestamp)/(3600*12))
}
# our quality rank feature
function quality() {
expression: attribute(sourcequality)
}
# normalization factor for the weighted sum
function normalization() {
expression: query(textMatchWeight) + query(qualityWeight) + query(deservesFreshness)
}
# ranking function that runs over all matched documents, determined by the boolean query logic
first-phase {
expression: (query(textMatchWeight) * (nativeRank(title,body) + query(qualityWeight) * quality + query(deservesFreshness) * freshness))/normalization
}
summary-features: nativeRank(title,body) age(timestamp) freshness quality
}
}
We can override the weight of each signal at query time with the query api, passing down the weights:
/search/?query=vespa+ranking&datetime=now&ranking.profile=blog&input.query(textMatchWeight)=0.1&input.query(deservesFreshness)=0.85
It is also possible to override the user-defined rank-features in a custom searcher plugin, note that we also use the datetime parameter to be able to calculate the age of the document.
The summary-features allows us to have access to the individual ranking signals along with the hit's summary fields.