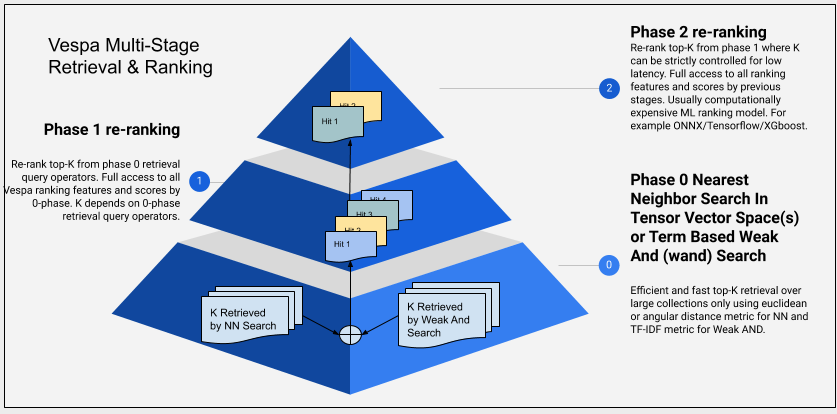
Vespa allows expressing multiphased retrieval and ranking of documents. The retrieval phase is done close to the data in the content nodes, while the ranking phase(s) can be done in the content nodes or in the stateless container after scatter-and-gather from content node(s). The retrieval part of a phased pipeline is expressed by using the query API and the ranking part is expressed by using the rank-profile in the schema.
- Retrieval: Top-k query operators, like weakAnd/wand and nearest neighbor search allow retrieval with sublinear complexity. These query operators use simple scoring functions that are computationally cheap to evaluate over Vespa indexes. Using the expressiveness of the Vespa query language, developers can combine multiple retrievers in the query, and expose the union of retrieved documents into Vespa ranking phases.
-
Per node ranking:The query specification retrieves documents and ranks them using declarative phases evaluated within
the content nodes:
- first-phase expression; configured in rank-profile. This phase is evaluated for all hits retrieved by the query logic. This phase can also remove retrieved documents using rank-score-drop-limit.
- second-phase ranking; configured in rank-profile. Optionally re-rank the top-scoring hits from the first-phase ranking using a more complex expression. The total-rerank-count sets a strict upper bound on the number of documents that are re-ranked in total over the nodes.
- Global ranking:Following the per content node local ranking phases, re-ranking can occur after the content nodes have returned the merged top-scoring hits to the stateless container. This phase is specified using a global-phase expression in the rank-profile. Additionally, the global-phase can conduct cross-hit normalization to combine unrelated scoring methods.
- Finally, for customized ranking that is difficult to express in declarative phases, one can implement re-ranking using reranking in searcher.
First-phase ranking on content nodes
Normally, you will always start by having one ranking expression
that is evaluated on the content nodes. This is configured in
the rank-profile section of a
schema
as a first-phase expression. This expression can
use various rank features
with information extracted during the matching phase to evaluate
the relevance of each document. The first-phase expression
is computed for every document retrieved by the query. The computational cost
is bounded by the number of documents exposed to the ranking phase on each content node multiplied with
the complexity of the first-phase expression; therefore the expression
needs to be simple and cheap to allow scaling to large amounts of retrieved docs. Alternatively,
use retrieval operators that will expose only the top-k hits to the first-phase expression.
Two-phase ranking on content nodes
While some use cases only require one (simple) first-phase
ranking expression, for more advanced use cases it's possible to
add a second-phase ranking expression in a
rank-profile
in the schema.
This enables more expensive computations than would be feasible
to run as a first-phase computation, with predictable
upper bounds for the cost.
By default, second-phase ranking (if specified) is evaluated for the 100 best hits from the first-phase ranking per content node. The number that is reranked over all nodes can be set by total-rerank-count.
schema myapp {
…
rank-profile title-freshness inherits default {
first-phase {
expression {
bm25(title) + 3*freshness(timestamp)
}
}
second-phase {
expression {
xgboost("my-model.json")
}
total-rerank-count: 50
}
}
}
In this example, the first phase uses the text matching feature bm25 scoped to the title field plus one of the built-in document rank feature named freshness over a timestamp field which stores the epoch time in second resolution. For each content node, the top 50 hits from the first phase function is re-ranked using a trained xgboost model.
Using a global-phase expression
Using a rank expression configured as a
global-phase
in the rank-profile section of a schema, you can add
a ranking phase that will run in the stateless container after
gathering the best hits from the content node phases; this can be used
instead of or in addition to
second-phase ranking.
The global-phase can also perform
cross-hit normalization
to combine unrelated scoring methods.
By default, global-phase ranking runs on the 100 globally best hits for
a schema; this can be tuned in the rank-profile using
rerank-count
or per-query using the
ranking.globalPhase.rerankCount
query property.
This phase is optimized for inference with ONNX models, taking some input data from the document and some from the query, and finding a score for how well they match. A typical use case is re-ranking using cross-encoders.
It's possible to specify gpu-device to get GPU-accelerated computation of the model as well. You can compute or re-shape the inputs to the ONNX model in a function if necessary, and use the output in some further calculation to compute the final score.
If you have large and complex expressions (including xgboost, lightgbm), instead of an ONNX model, it's more efficient to use the highly optimized second-phase computation on content nodes. This is also true for sub-expressions that require lots of vector data, moving vector data across the network is expensive.
By adding the feature to match-features in the ranking profile, the global-phase expression can re-use the function output without the complexity of transferring the data across the network and performing inference in the stateless container (which is less optimized).
schema myapp {
document myapp {
field per_doc_vector type tensor<float>(x[784]) {
indexing: attribute
}
…
}
…
rank-profile with-global-model inherits default {
inputs {
query(per_query_vector) tensor<float>(d0[32])
}
first-phase {
expression: bm25(title)
}
function my_expensive_function() {
expression: # some expensive computation better done on content nodes
}
function per_doc_input() {
# simple reshaping: ONNX input wants the dimension name "d0"
expression: rename(attribute(per_doc_vector), x, d0)
}
onnx-model my_ranking_model {
file: files/my_ranking_model.onnx
input "model_input_1": per_doc_input
input "model_input_2": query(per_query_vector)
output "model_output_1": out
}
global-phase {
expression {
my_expensive_function + sum(onnx(my_ranking_model).out)
}
rerank-count: 50
}
match-features {
my_expensive_function
}
}
}
In the example above, my_expensive_function will be evaluated on the content nodes for the 50 top-ranking documents from the first-phase so that the global-phase does not need to re-evaluate.
Cross-hit normalization including reciprocal rank fusion
The ranking expressions configured for global-phase may perform cross-hit normalization of input rank features or functions. This is designed to make it easy to combine unrelated scoring methods into one final relevance score. The syntax looks like a special pseudo-function call:
-
normalize_linear(my_function_or_feature) -
reciprocal_rank(my_function_or_feature) -
reciprocal_rank(my_function_or_feature, k) -
reciprocal_rank_fusion(score_1, score_2 ...)
The normalization will be performed across the hits that global-phase reranks (see configuration above). This means that first, the input (my_function_or_feature) is computed or extracted from each hit that global-phase will rerank; then the normalization step is applied; afterwards, when computing the actual global-phase expression, the normalized output is used. As an example, assume some text fields with bm25 enabled, an ONNX model (from the example in the previous section), and a "popularity" numeric attribute:
rank-profile with-normalizers inherits with-global-model {
function my_bm25_sum() {
expression: bm25(title) + bm25(abstract)
}
function my_model_out() {
expression: sum(onnx(my_ranking_model).out)
}
global-phase {
expression {
normalize_linear(my_bm25_sum) + normalize_linear(my_model_out) + normalize_linear(attribute(popularity))
}
rerank-count: 200
}
}
The normalize_linear normalizer takes a single argument, which must be
a rank-feature or the name of a function. It computes the maximum and minimum
values of that input and scales linearly to the range [0, 1], basically using
the formula output = (input - min) / (max - min)
The reciprocal_rank normalizer takes one or two arguments; the first
must be a rank-feature or the name of a function, while the second (if present)
must be a numerical constant, called k with default value 60.0.
It sorts the input values and finds their rank (so the highest score gets
rank 1, next highest 2, and so on). The output from reciprocal_rank is computed
with the formula output = 1.0 / (k + rank) , so note that even the best
input only gets 1.0 / 61 = 0.016393 as output with the default k.
The reciprocal_rank_fusion pseudo-function takes at least two arguments
and expands to the sum of their reciprocal_rank; it's just a
convenient way to write
reciprocal_rank(a) + reciprocal_rank(b) + reciprocal_rank(c)
as
reciprocal_rank_fusion(a,b,c)
for example.
See the Simple Hybrid Search with ColBERT sample application for a practical example of using reciprocal rank fusion.
Stateless re-ranking
If the logic required is not suited for the global-phase above, it's possible to write stateless searchers which can re-rank hits using any custom scoring function or model. The searcher can also blend and re-order hits from multiple sources when using federation of content sources.
The searcher might request rank features calculated by the content nodes to be returned along with the hit fields using summary-features. The features returned can be configured in the rank-profile as summary-features.
The number of hits is limited by the query api hits parameter and maxHits setting. The hits available for container-level re-ranking are the global top-ranking hits after content nodes have retrieved and ranked the hits, and global top-ranking hits have been found by merging the responses from the content nodes.
Top-K Query Operators
If the first-phase ranking function can be approximated as a simple linear function, and the query mode is weakAnd, the Weak And/WAND implementations in Vespa allows avoiding fully evaluating all the documents matching the query with the first-phase function. Instead, only the top-K hits using the internal wand scoring are exposed to the first-phase ranking expression.
The nearest neighbor search operator is also a top-k retrieval operator, and the two operators can be combined in the same query.
Choosing phased ranking functions
A good quality ranking expression will for most applications consume too much CPU to be runnable on all retrieved or matched documents within the latency budget/SLA. The application ranking function should hence in most cases be a second-phase function. The task then becomes to find a first-phase function, which correlates sufficiently well with the second-phase function.
Rank phase statistics
Use match-features and summary-features to export detailed match- and rank-information per query. This requires post-processing and aggregation in an external system for analysis.
To evaluate how well the document corpus matches the queries, use mutable attributes to track how often each document survives each match- and ranking-phase. This is aggregated per document and makes it easy to analyse using the query and grouping APIs in Vespa - and no other processing/storage is required.
A mutable attribute is a number where an operation can be executed in 4 phases:
- on-match
- on-first-phase
- on-second-phase
- on-summary
The common use case is to increase the value by 1 for each execution. With this, it is easy to evaluate the document's performance to the queries, e.g. find the documents that appear in most queries, or the ones that never matched - run a query and order by the mutable attribute.
This example is based on the album-recommendation sample application
(see deploying an application).
It uses 4 attributes that each track how many times a document participates in any of the 4 phases.
This is tracked only if using rank-profile rank_albums_track in the query:
schema music {
document music {
field artist type string {
indexing: summary | index
}
field album type string {
indexing: summary | index
}
field year type int {
indexing: summary | attribute
}
field category_scores type tensor<float>(cat{}) {
indexing: summary | attribute
}
}
field match_count type long {
indexing: attribute | summary
attribute: mutable
}
field first_phase_count type long {
indexing: attribute | summary
attribute: mutable
}
field second_phase_count type long {
indexing: attribute | summary
attribute: mutable
}
field summary_count type long {
indexing: attribute | summary
attribute: mutable
}
fieldset default {
fields: artist, album
}
rank-profile rank_albums inherits default {
first-phase {
expression: sum(query(user_profile) * attribute(category_scores))
}
second-phase {
expression: attribute(year)
rerank-count: 1
}
summary-features: attribute(year)
}
rank-profile rank_albums_track inherits rank_albums {
mutate {
on-match { match_count += 1 }
on-first-phase { first_phase_count += 1 }
on-second-phase { second_phase_count += 1 }
on-summary { summary_count += 1 } # this only happens when summary-features are present!
}
}
rank-profile rank_albums_reset_on_match inherits rank_albums {
mutate {
on-match { match_count = 0 }
}
}
rank-profile rank_albums_reset_on_first_phase inherits rank_albums {
mutate {
on-match { first_phase_count = 0 }
}
}
rank-profile rank_albums_reset_on_second_phase inherits rank_albums {
mutate {
on-match { second_phase_count = 0 }
}
}
rank-profile rank_albums_reset_on_summary inherits rank_albums {
mutate {
on-match { summary_count = 0 }
}
}
}
$ vespa query \ "select * from music where album contains 'head'" \ "ranking=rank_albums_track"
Usage
The framework is flexible in use; the normal use case is:
-
Reset the mutable attribute on all content nodes -
use searchPath
to make sure all nodes are reset by sending a query using a rank profile that resets the value.
For each phase, run a query that matches all documents, and reset the attribute - e.g.:
$ for phase in match first_phase second_phase summary; do \ for node in {0..3}; do vespa query \ "select * from music where true" \ "ranking=rank_albums_reset_on_$phase" \ "model.searchPath=$node/0"; \ done \ doneAlternatively, run a query against a group and verify that coverage is 100%. -
Run query load, using the tracking rank-profile, like
rank_albums_trackabove - Run queries using sorting or grouping on the mutable attributes.
To initialize a mutable attribute with a different value than 0 when a document is PUT, use:
field match_count type long {
indexing: 7 | to_long | attribute | summary # Initialized to 7 for a new document. The default is 0.
attribute: mutable
}
To dump values fast, from memory only (assuming the schema has an id field):
document-summary rank_phase_statistics {
summary id {}
summary match_count {}
summary first_phase_count {}
summary second_phase_count {}
summary summary_count {}
}
$ vespa query \ "select * from music where true" \ "presentation.summary=rank_phase_statistics"