This is the list of the rank features in Vespa. These features are available during document ranking for combination into a complete rank score by a ranking expression. The features are a combination of coarse grained features suitable for handwritten expressions, and finer grained features suitable for machine learning.
See also the overview of the ranking framework, and rank feature configuration parameters. Notes:
- Types: All rank feature values are doubles or tensors. Integers are converted to exact whole value doubles. String values are converted to exact whole value doubles using a hash function. String literals in ranking expressions are converted using the same hash function, to enable equality tests on string values.
- Features which are normalized are between 0 and 1, where 0 is always the minimum and 1 the maximum. Normalized features should normally be preferred because they are more easily combined by ranking expressions into a complete normalized score.
- A query may override any rank feature value by submitting that value as a feature with the query.
- Some features have parameters. It is always allowed to quote parameters with ". Nested quotes are not allowed and must be escaped using \. Parameters that can be parsed as feature names may be left unquoted. Examples: foo(bar(baz(5.5))), foo("bar(\"baz(\\\"5.5\\\")\")"), foo("need quote")
Feature list
Query features | ||
| Feature name | Default | Description |
|---|---|---|
| query(value) | 0 |
An application specific feature submitted with the query, see using the query feature. |
| term(n).significance | 0 | A normalized number (between 0.0 and 1.0) describing the significance of the term; used as a multiplier or weighting factor by many other text matching rank features. This should ideally be set by a searcher in the container for global correctness as each node will estimate the significance values from the local corpus. Use the Java API for significance or YQL annotation for significance. As a fallback, a significance based on Robertson-Sparck-Jones term weighting is used; it is logarithmic from 1.0 for rare terms down to 0.5 for common terms (those occurring in every document seen). Note that "rare" is defined as a frequency of 0.000001 or less. This is the term document frequency (how many documents contain the term out of all documents that can be observed), so you cannot get 1.0 as the fallback until you actually have a large number of documents (minimum 1 million) in the same search process. See numTerms config. |
| term(n).weight | 100 | The importance of matching this query term given in the query |
| term(n).connectedness | 0.1 |
The normalized strength with which this term is connected to the previous term in the query. Must be assigned to query terms in a searcher using the Java API for connectivity or YQL annotation for connectivity. |
| queryTermCount | 0 |
The total number of terms in this query, including both user and synthetic terms in all fields. |
Document features | ||
| Feature name | Default | Description |
| fieldLength(name) | 1000000 |
The number of terms in this field if one or more query term matched the field, 1000000 if no query term matched the field. |
| averageFieldLength(name) | n/a |
The average length, in number of terms, of the indexed field name, as computed from the local content node index (in memory or on disk). This is the same index statistic that BM25 uses by default for field length normalization (the avg_field_len term), exposed here so it can be used for debugging and in custom text ranking formulas such as Bayesian BM25. name must be a configured index field; it may be single-value, array or weighted-set. Referencing an unknown field or a non-index field is a configuration error. For multi-value fields the field length is the sum of the lengths over all elements, consistent with bm25.
Note:
The value is a per-content-node statistic computed locally; it is
not cluster-wide and may differ between nodes. It also reflects the actual index contents and is
not affected by the
bm25(field).averageFieldLength rank-property override.
|
| queryTermDocumentFrequency(name) | empty tensor |
A
The tensor has one cell per query term that searches name; terms that do not search the field
are not included. Each cell is labeled with the index of the term in the query (as a string, starting at 0),
and the labels keep their original query-term index rather than being renumbered.
For a term that searches several fields, the cell holds the frequency for the specific field (here,
Example: for a query where term 0 and term 2 search the
tensor<double>(term{}):{ {term:0}:1200.0, {term:2}:57.0 }
Each value is a query-provided override from the significance model if one is present, otherwise the local content node index statistic — the same value BM25 uses. See also term(n).significance, which is derived from this document frequency. name must be a configured index field; referencing an unknown or non-index field is a configuration error, and the tensor is empty when no query term searches the field.
Note:
The value is a per-content-node statistic unless overridden by the
significance model, so it may differ between nodes. In streaming
search, non-overridden values are 0.
|
| attribute(name) | null |
The value of a tensor or single value numeric attribute or null/NaN if not set. Use isNan() to check if value is not defined. Using undefined values in ranking expressions leads to undefined behavior. |
| attribute(name,n) | 0 |
The value at index n (base 0) of a numeric array attribute with the given name. Note that the index number must be explicit, it cannot be the output of an expression function. The order of the items in an array attribute is the same as the order they have in the input feed. If items are added using partial updates they are added to the end of the existing items list. |
| attribute(name,key).weight | 0 | The weight found at a given key in a weighted set attribute |
| attribute(name,key).contains | 0 |
1 if the given key is present in a weighted set attribute, 0 otherwise |
| attribute(name).count | 0 | The number of elements in the attribute with the given name. |
| tensorFromWeightedSet(source,dimension) | empty tensor |
Creates a Example: Given the weighted set:
{key1:0, key2:1, key3:2.5}
tensorFromWeightedSet(attribute(myField), dim) produces:
tensor<double>(dim{}):{ {dim:key1}:0.0, {dim:key2}:1.0, {dim:key3}:2.5} }
Note:
This creates a temporary tensor,
and has build cost and extra memory is touched.
Tensor evaluation is most effective when the cell types of all tensors are equal -
use cell_cast to enable optimizations.
Also, duplicating the field in the schema to a native tensor instead of creating from a set
can increase performance.
|
| tensorFromLabels(attribute,dimension) | empty tensor |
Creates a
Example: Given an attribute field [v1, v2, v3] tensorFromLabels(attribute(myField), dim) produces:
tensor<double>(dim{}):{ {dim:v1}:1.0, {dim:v2}:1.0, {dim:v3}:1.0 }
See tensorFromWeightedSet for performance notes. |
| tensorFromStructs(attribute,key,value,type) | empty tensor |
Creates a Example: Given an tensorFromStructs(attribute(items), name, price, float)
tensor<float>(name{}):{ {name:apple}:1.5, {name:banana}:0.75, {name:cherry}:2.25 }
Example: Integer keys and float values: tensorFromStructs(attribute(ids), id, score, double)
tensor(id{}):{ {id:100}:10.5, {id:200}:20.75, {id:300}:30.25 }
The function takes at least four arguments; it's possible to use several key
arguments to get multiple mapped dimensions. If the tensorFromStructs(attribute(items), name, region, price, float)to get a tensor<float>(name{},region{}) making it possible to have
different prices of apples in different regions.
Details:
Empty or missing arrays yield an empty tensor of the requested type.
The first argument must be an See tensorFromWeightedSet for performance notes. |
| tensorFromLabelsWithOffset(attribute,label-dimension,offset-dimension) | empty tensor |
Creates a
Example: Given an attribute field [v1, v2, v3] tensorFromLabelsWithOffset(attribute(myField), dim, off) produces:
tensor<float>(dim{},off{}):{ {dim:v1,off:0}:1.0, {dim:v2,off:1}:1.0, {dim:v3,off:2}:1.0 }
|
Field match features - normalized | ||
| fieldMatch features provide a good measure of the degree to which a query matches the text of a field, but are expensive to calculate and therefore often only suitable for second-phase ranking expressions. See the string segment match document for details on the algorithm computing this rank-feature set. Note that even using a fine-grained sub features like fieldMatch(name).absoluteOccurrence will have the same complexity and cost as using the general top level fieldMatch(name) feature. | ||
| Feature name | Default | Description |
| fieldMatch(name) | 0 |
A normalized measure of the degree to which this query and field matched
(default, the long name of this is |
| fieldMatch(name).proximity | 0 | Normalized proximity - a value which is close to 1 when matched terms are close inside each segment, and close to zero when they are far apart inside segments. Relatively more connected terms influence this value more. This is absoluteProximity/average connectedness for the query terms for this field. Note that if all the terms are far apart, the proximity will be 1, but the number of segments will be high. Proximity is only concerned with closeness within segments, a total score must also take the number of segments into account. |
| fieldMatch(name).completeness | 0 |
The normalized total completeness, where field completeness is more important:
|
| fieldMatch(name).queryCompleteness | 0 | The normalized ratio of query tokens matched in the field: matches/query terms searching this field |
| fieldMatch(name).fieldCompleteness | 0 | The normalized ratio of query tokens which was matched in the field: matches/fieldLength |
| fieldMatch(name).orderness | 0 |
A normalized metric of how well the order of the terms agrees in the chosen segments:
|
| fieldMatch(name).relatedness | 0 |
|
| fieldMatch(name).earliness | 0 |
A normalized measure of how early the first segment occurs in this field. |
| fieldMatch(name).longestSequenceRatio | 0 |
A normalized metric of the relative size of the longest sequence:
|
| fieldMatch(name).segmentProximity | 0 |
A normalized metric of the closeness (inverse of spread) of segments in the field:
|
| fieldMatch(name).unweightedProximity | 0 |
The normalized proximity of the matched terms, not taking term connectedness into account. This number is close to 1 if all the matched terms are following each other in sequence, and close to 0 if they are far from each other or out of order. |
| fieldMatch(name).absoluteProximity | 0 |
Returns the normalized proximity of the matched terms, weighted by the connectedness of the query terms. This number is 0.1 if all the matched terms are and have default or lower connectedness, close to 1 if they are following in sequence and have a high connectedness, and close to 0 if they are far from each other in the segments or out of order. |
| fieldMatch(name).occurrence | 0 | Returns a normalized measure of the number of occurrences of the terms of the query. This is 1 if there are many occurrences of the query terms in absolute terms, or relative to the total content of the field, and 0 if there are none. This is suitable for occurrence in fields containing regular text. |
| fieldMatch(name).absoluteOccurrence | 0 | Returns a normalized measure of the number of occurrence of the terms of the query: $$\frac{\sum_{\text{all query terms}}(min(\text{number of occurrences of the term},maxOccurrences))}{(\text{query term count} × 100)}$$ This is 1 if there are many occurrences of the query terms, and 0 if there are none. This number is not relative to the field length, so it is suitable for uses of occurrence to denote relative importance between matched terms (i.e. fields containing keywords, not normal text). |
| fieldMatch(name).weightedOccurrence | 0 |
Returns a normalized measure of the number of occurrence of the terms of the query, weighted by term weight. This number is close to 1 if there are many occurrences of highly weighted query terms, in absolute terms, or relative to the total content of the field, and 0 if there are none. |
| fieldMatch(name).weightedAbsoluteOccurrence | 0 | Returns a normalized measure of the number of occurrence of the terms of the query, taking weights into account so that occurrences of higher weighted query terms has more impact than lower weighted terms. This is 1 if there are many occurrences of the highly weighted terms, and 0 if there are none. This number is not relative to the field length, so it is suitable for uses of occurrence to denote relative importance between matched terms (i.e. fields containing keywords, not normal text). |
| fieldMatch(name).significantOccurrence | 0 | Returns a normalized measure of the number of occurrence of the terms of the query in absolute terms, or relative to the total content of the field, weighted by term significance. This number is 1 if there are many occurrences of the highly significant terms, and 0 if there are none. |
Field match features - normalized and relative to the whole query | ||
| Feature name | Default | Description |
| fieldMatch(name).weight | 0 | The normalized weight of this match relative to the whole query: The sum of the weights of all matched terms/the sum of the weights of all query terms. If all the query terms were matched, this is 1. If no terms were matched, or these matches has weight zero this is 0. As the sum of this number over all the terms of the query is always 1, sums over all fields of normalized rank features for each field multiplied by this number for the same field will produce a normalized number. Note that this scales with the number of matched query terms in the field. If you want a component which does not, divide by matches. |
| fieldMatch(name).significance | 0 | Returns the normalized term significance of the terms of this match relative to the whole query: The sum of the significance of all matched terms/the sum of the significance of all query terms. If all the query terms were matched, this is 1. If no terms were matched, or if the significance of all the matched terms is zero, this number is zero. This metric has the same properties as weight. See the term(n).significance feature for how the significance for a single term is calculated. |
| fieldMatch(name).importance | 0 |
Returns the average of significance and weight. This has the same properties as those metrics. |
Field match features - not normalized | ||
| Feature name | Default | Description |
| fieldMatch(name).segments | 0 |
The number of field text segments which are needed to match the query as completely as possible |
| fieldMatch(name).matches | 0 |
The total number of query terms which was matched in this field |
| fieldMatch(name).degradedMatches | 0 |
The number of degraded query terms which was matched in this field. A degraded term is a term where no occurrence information is available during calculation. The number of degraded matches is less than or equal to the total number of matches. |
| fieldMatch(name).outOfOrder | 0 |
The total number of out of order token sequences within matched field segments |
| fieldMatch(name).gaps | 0 |
The total number of position jumps (backward or forward) within field segments |
| fieldMatch(name).gapLength | 0 | The summed length of all gaps within segments |
| fieldMatch(name).longestSequence | 0 |
The size of the longest matched continuous, in-order sequence in the field |
| fieldMatch(name).head | 0 |
The number of tokens in the field preceding the start of the first matched segment |
| fieldMatch(name).tail | 0 |
The number of tokens in the field following the end of the last matched segment |
| fieldMatch(name).segmentDistance | 0 |
The sum of the distance between all segments making up a match to the query, measured as the sum of the number of token positions separating the start of each field adjacent segment. |
Query and field similarity | ||
| Normalized feature set measuring the approximate similarity between a field and the query. These features are suitable in cases where the query is as large as the field (i.e. is a document) such that we are interested in the similarity between the query and the entire field. They are cheap to compute even if the query is large. | ||
| Feature name | Default | Description |
| textSimilarity(name) | 0 | A weighted sum of the individual similarity measures. |
| textSimilarity(name).proximity | 0 |
A measure of how close together the query terms appear in the field. |
| textSimilarity(name).order | 0 |
A measure of the order in which the query terms appear in the field compared to the query. |
| textSimilarity(name).queryCoverage | 0 |
A measure of how much of the query the field covers when a single term from the field can only cover a single term in the query. Query term weights are used during normalization. |
| textSimilarity(name).fieldCoverage | 0 |
A measure of how much of the field the query covers when a single term from the query can only cover a single term in the field. |
Query term and field match features | ||
| Feature name | Default | Description |
| fieldTermMatch(name,n).firstPosition | 1000000 |
The position of the first occurrence of this query term in this index field. numTerms configuration |
| fieldTermMatch(name,n).occurrences | 0 |
The number of occurrences of this query term in this index field |
| matchCount(name) | 0 |
Returns number of times any term in the query matches this index/attribute field. |
| matches(name) | 0 |
Returns 1 if the index/attribute field with the given name is matched by the query. |
| matches(name,n) | 0 |
Returns 1 if the index/attribute field with the given name is matched by the query term with position n. |
| termDistance(name,x,y).forward | 1000000 |
The minimum distance between the occurrences of term x and term y in this index field. Term x occurs before term y. |
| termDistance(name,x,y).forwardTermPosition | 1000000 |
The position of the occurrence of term x in this index field used for the forward distance. |
| termDistance(name,x,y).reverse | 1000000 |
The minimum distance between the occurrences of term y and term x in this index field. Term y occurs before term x. |
| termDistance(name,x,y).reverseTermPosition | 1000000 |
The position of the occurrence of term y in this index field used for the reverse distance. |
Features for indexed multivalue string fields | ||
| Feature name | Default | Description |
| elementCompleteness(name).completeness | 0 |
A weighted combination of fieldCompleteness and queryCompleteness for the element in the field that produces the highest value for this output after the elements weight is factored in. The weighting can be adjusted using elementCompleteness(name).fieldCompletenessImportance. |
| elementCompleteness(name).fieldCompleteness | 0 |
The field completeness of the best matching element. This is calculated as:
|
| elementCompleteness(name).queryCompleteness | 0 |
The query completeness of the best matching element. This is calculated as:
|
| elementCompleteness(name).elementWeight | 0 | The weight of the best matching element, starting from the default - i.e., negative weights will return 0. |
| elementSimilarity(name) | 0 |
Aggregated similarity between the query and individual field elements.
The same sub-scores used by the This is a flexible feature; how sub-scores are combined for each element and how element scores are aggregated may be configured. You may also add additional outputs if you want to capture multiple signals from a single field. Use elementSimilarity to customize this feature. |
Attribute match features - normalized | ||
| Feature name | Default | Description |
| attributeMatch(name) | 0 |
A normalized measure of the degree to which this query and field matched. This is currently the same as completeness.
Note that depending on what the attribute is used for, this may or may not be a suitable metric.
If the attribute is a weighted set representing counts of items (like tags),
|
| attributeMatch(name).completeness | 0 |
The normalized total completeness, where field completeness is more important:
|
| attributeMatch(name).queryCompleteness | 0 |
The query completeness for this attribute:
|
| attributeMatch(name).fieldCompleteness | 0 |
The normalized ratio of query tokens which was matched in the field.
For arrays: |
| attributeMatch(name).normalizedWeight | 0 |
A number which is close to 1 if the attribute weights of most matches in a weighted set are high (relative to maxWeight), 0 otherwise |
| attributeMatch(name).normalizedWeightedWeight | 0 |
A number which is close to 1 if the attribute weights of most matches in a weighted set are high (relative to maxWeight), and where highly weighted query terms has more impact, 0 otherwise |
| closeness(dimension,name) | 0 | Used with the nearestNeighbor query operator. A number which is close to 1 when a vector in the document tensor is close to the vector given in the query. The indexed dimension representing a vector in document and query tensors must be identical.
Note:
closeness() is calculated only based on the vectors
matched with nearestNeighbor operator.
This means that the value of closeness() is not necessarily calculated based on the same vector
returned by closest() rank feature if nearestNeighbor search is approximate, as
closest() will be calculated based on all specified document vectors.
The output value is $$ closeness(dimension,name) = \frac{1.0}{1.0 + distance(dimension,name)}$$ When the tensor field stores multiple vectors per document, the minimum distance between the vectors of a document and the query vector is used in the calculation above. |
| freshness(name) | 0 | A number which is close to 1 if the timestamp in attribute name is recent compared to the current time compared to maxAge:
Scales linearly with age, see freshness plot. |
| freshness(name).logscale | 0 |
A logarithmic-shaped freshness; also goes from 1 to 0, but looks like freshness plot.
The function is based on $$\frac{log(maxAge + scale) - log(age(name) + scale)}{log(maxAge + scale) - log(scale)}$$ where scale is defined using halfResponse and maxAge: $$\frac{-halfResponse^2}{2 × halfResponse - maxAge}$$
When |
Attribute match features - normalized and relative to the whole query | ||
| Feature name | Default | Description |
| attributeMatch(name).weight | 0 |
This has the same semantics as fieldMatch(name).weight. |
| attributeMatch(name).significance | 0 |
This has the same semantics as fieldMatch(name).significance. |
| attributeMatch(name).importance | 0 |
Returns the average of significance and weight. This has the same properties as those metrics. |
Attribute match features - not normalized | ||
| Feature name | Default | Description |
| attributeMatch(name).matches | 0 | The number of query terms which was matched in this attribute |
| attributeMatch(name).totalWeight | 0 |
The sum of the weights of the attribute keys matched in a weighted set attribute |
| attributeMatch(name).averageWeight | 0 | totalWeight/matches |
| attributeMatch(name).maxWeight | 0 |
The maximum weight of the attribute keys matched in a weighted set attribute |
| closest(name) | {} | Used with the nearestNeighbor query operator and a tensor field attribute name storing multiple vectors per document. This feature returns a tensor with one or more mapped dimensions and one point with a value of 1.0, where the label of that point indicates which document vector was closest to the query vector in the nearest neighbor search.
Given a tensor field with type
tensor<float>(m{}):{ 3: 1.0 }
In this example, the document vector with label 3 in the mapped m dimension was closest to the query vector. |
| closest(name,label) | {} | Used with the nearestNeighbor query operator tagged with a label label and a tensor field attribute name storing multiple vectors per document. See closest(name) for details. |
| distance(dimension,name) | max double value | Used with the nearestNeighbor query operator. A number which is close to 0 when a point vector in the document is close to a matching point vector in the query. The document vectors and the query vector must be the same tensor type, with one indexed dimension of size N, representing a point in an N-dimensional space.
The output value depends on the distance metric used. The default is the Euclidean distance between the "n"-dimensional query point "d" and the point "d" in the document tensor field: $$ distance = \sqrt{\sum_{i=1}^n (q_i - d_i)^2} $$ When the tensor field stores multiple vectors per document, the minimum distance between the vectors of a document and the query vector is used in the calculation above. |
| age(name) | 10B |
The document age in seconds relative to the unit time value stored in the attribute having this name |
Features combining multiple fields and attributes | ||
| Feature name | Default | Description |
| match | 0 |
A normalized average of the fieldMatch and attributeMatch scores of all the searched fields and attributes, where the contribution of each field and attribute is weighted by its weight setting. |
| match.totalWeight | 0 |
The sum of the weight settings of all the field and attributes searched by the query |
| match.weight.name | 100 | The (schema) weight setting of a field or attribute |
Rank scores | ||
| Feature name | Default | Description |
| bm25(field) | 0 |
Calculates the Okapi BM25 ranking function over the given indexed string field. This feature is cheap to compute, about 3-4 times faster than nativeRank, while still providing a good rank score quality wise. This feature is a good candidate for usage in a first phase ranking function when ranking text documents. Note that the field must be enabled to be used with the bm25 feature; set the enable-bm25 flag in the index section of the field definition. See the BM25 Reference for more detailed information. |
| elementwise(bm25(field),dimension,cell_type) | tensor<cell_type>(dimension{}):{} |
Calculates the Okapi BM25 ranking function over each element in the given multi-valued indexed string field and creates a tensor with a single mapped dimension containing the bm25 score for each matching element. The element indexes (starting at 0) are used as dimension labels. This feature is more expensive than bm25, does not need the enable-bm25 flag and can be tuned with rank properties.
The cell_type parameter can be omitted (the default value is
Example: If the
"elementwise(bm25(content),x,float)": {
"type": "tensor
|
| nativeRank | 0 |
A reasonably good rank score which is computed cheaply by Vespa. This value only is a good candidate first phase ranking function, and is the default used in the default rank profile. The value computed by this function may change between Vespa versions. See the native rank reference for more information. |
| nativeRank(field,...) | 0 |
Same as nativeRank, but only the given set of fields are used in the calculation. |
| nativeFieldMatch | 0 |
Captures how well query terms match in index fields. Used by nativeRank. See the native rank reference for more information. |
| nativeFieldMatch(field,...) | 0 |
Same as nativeFieldMatch, but only the given set of index fields are used in the calculation. |
| nativeProximity | 0 |
Captures how near matched query terms occur in index fields. Used by nativeRank. See the native rank reference for more information. |
| nativeProximity(field,...) | 0 |
Same as nativeProximity, but only the given set of index fields are used in the calculation. |
| nativeAttributeMatch | 0 |
Captures how well query terms match in attribute fields. Used by nativeRank. See the native rank reference for more information. |
| nativeAttributeMatch(field,...) | 0 |
Same as nativeAttributeMatch, but only the given set of attribute fields are used in the calculation. |
| nativeDotProduct(field) | 0 | Calculates the sparse dot product between query term weights and match weights for the given field. Example: A weighted set string field X:
"X": {
"x": 10,
"y": 20,
"z": 30
}
For the query (x!2 OR y!4), the nativeDotProduct(X) feature will have the value 100 (10*2+20*4) for that document.
Note:
nativeDotProduct and nativeDotProduct(field)
is less optimal for computing the dot product -
consider using dotProduct(name,vector).
|
| nativeDotProduct | 0 | Calculates the sparse dot product between query term weights and match weights as above, but for all term/field combinations. |
| firstPhase | 0 |
The value of the rank score calculated in the first phase (unavailable in first phase ranking expressions) |
| secondPhase | 0 |
The value of the rank score calculated in the second phase (unavailable in first phase and second phase ranking expressions) |
| firstPhaseRank | max double value |
The rank of the document after first phase within the content node when selecting which documents to rerank in second phase. The best document after first phase has rank 1, the second best 2, etc. The feature returns the default value for documents not selected for second phase ranking and for unsupported cases (streaming search, summary features, first phase expressions). Multiple documents can have the same firstPhaseRank value in multi-node configurations. |
| firstPhaseMax | -infinity |
The maximum first-phase rank score among all hits matched on the content node. Calculated locally on each content node, so may yield different results on different nodes. |
| relevanceScore | - |
The value of the rank score calculated either in the first or (when defined) in the second phase (unavailable in first phase and second phase ranking expressions) (since 8.559.30). |
Global features | ||
| Feature name | Default | Description |
| globalSequence | n/a |
A global sequence number computed as (1 << 48) - (LocalDocumentId << 16 || distribution-key). This will give a global sequence to documents. This is a cheap way of having stable ordering of documents. Note the large range of this value. Also note that if the system is not stable, e.g. if documents move around due to new nodes coming in, or nodes being removed, it will no longer be stable as documents might be found in a different replica. If you need true global ordering we suggest assigning a unique numeric id to your documents as an attribute field and use the attribute(name) feature. |
| now | n/a | Time at which the query is executed in unix-time (seconds since epoch) |
| num_docs_indexed | n/a |
The local document count used as BM25's total document count when no per-term document-frequency override is present. This is the N term used by the BM25 inverse document frequency calculation.
Note:
The value is a per-content-node statistic computed locally; it is
not cluster-wide and may differ between nodes. For
streaming search, this feature returns 1.
|
| random | n/a |
A pseudorandom number in the range [0,1> which is drawn once per document during rank evaluation.
By default, the current time in microseconds is used as a seed value.
Users can specify a seed value by setting
random.seed in the rank profile.
If you need several independent random numbers the feature can be named like this:
|
| random.match | n/a |
A pseudorandom number in the range [0,1> that is stable for a given hit.
This means that a hit will always receive the same random score (on a single node).
If it is required that the scores be different between different queries,
specify a seed value dependent upon the query. By default, the seed value is 1024.
Users can specify a seed value by adding the query parameter
rankproperty.random.match.seed=<value>.
If you need several independent random numbers the feature can be named like this:
|
| randomNormal(mean,stddev) | 0.0,1.0 |
Same as random, except the random number is drawn from
the Gaussian distribution using the supplied mean and stddev parameters.
Can be called without parameters; default values are assumed.
Seed is set similarly as random.
If you need several independent random numbers with the same parameters,
the feature can be named like this: |
| randomNormalStable(mean,stddev) | 0.0,1.0 |
Same as randomNormal, except that the generated number is stable for a given hit, similar to random.match. |
| constant(name) | n/a |
Returns the constant tensor value. |
Match operator scores | ||
| See Raw scores and query item labeling | ||
| Feature name | Default | Description |
| rawScore(field) | 0 | The sum of all raw scores produced by match operators for this field. |
| itemRawScore(label) | 0 | The raw score produced by the query item with the given label. |
Geo search | ||
|
These features are for ranking on the distances between geographical coordinates, i.e. points on the surface of the earth defined by latitude/longitude pairs. See the main documentation for
Geo Search.
Note:
Some of these features have the same names as features used with the nearestNeighbor query operator. Take care not to get them mixed up!
| ||
| Feature name | Default | Description |
| closeness(name) | 0 | A number which is close to 1 if the position in attribute name is close to the query position compared to maxDistance:
Scales linearly with distance, see closeness plot. |
| closeness(name).logscale | 0 |
A logarithmic-shaped closeness; like normal closeness it goes from 1 to 0,
but looks like closeness plot.
The function is a logarithmic fall-off based on
$$closeness(name).logscale = \frac{log(maxDistance + scale) - log(distance(name) + scale))}{(log(maxDistance + scale) - log(scale))}$$ where scale is defined using halfResponse and maxDistance: $$scale = \frac{halfResponse^2}{(maxDistance - 2 × halfResponse)}$$
When |
| distance(name) | 6400M |
The Euclidean distance from the query position to the given position attribute in millionths of degrees (about 10 cm). If there are multiple positions in the query, items that actually search in name is preferred. Also: if multiple query items search in name, or name is an array of positions, or both, the closest distance found is returned. |
| distance(name).km | 711648.5 |
As above, but scaled, so it uses the kilometer as unit of distance, instead of "micro-degrees". |
| distance(name).index | -1 |
The array index of the closest position found.
Useful when name is of |
| distance(name).latitude | 90 |
The latitude (geographical north-south coordinate) of the closest position found.
In range from -90.0 (South Pole) to +90.0 (North Pole).
Useful when name is of |
| distance(name).longitude | -180 |
The latitude (geographical east-west coordinate) of the closest position found.
In range from -180.0 (extreme west) to +180.0 (extreme east).
Useful when name is of |
| distanceToPath(name).distance | 6400M |
The Euclidean distance from a path through 2d space
given in the query to the given position attribute in
millionths of degrees. This is useful e.g. for finding the
closest locations to a given road. The query path is set in the
rankproperty.distanceToPath(name).path
query parameter, using syntax
Note:
For documents with multiple locations,
only the closest location is used for ranking purposes.
|
| distanceToPath(name).traveled | 1 |
The normalized distance along the query path traveled before intersection (0.0 indicates start of path, 0.5 is middle, and 1.0 is end of path). |
| distanceToPath(name).product | 0 |
The cross-product of the intersected path segment and the intersection-to-document vector.
Given that the document was found to lie closest to the path element |
Utility features | ||
| Feature name | Default | Description |
| foreach(dimension, variable, feature, condition, operation) | n/a |
foreach iterates over a set of feature output values and performs an operation on them. Only the values where the condition evaluates to true are considered for the operation. The result of this operation is returned.
Let's say you want to calculate the average score of the fieldMatch feature for all index fields, but only consider the scores larger than 0. Then you can use the following setup of the foreach feature:
Note that when using the conditions >a and <a the arguments must be quoted. You can also specify a ranking expression in the foreach feature by using the rankingExpression feature. The rankingExpression feature takes the expression as the first and only parameter and outputs the result of evaluating this expression. Let's say you want to calculate the average score of the squared fieldMatch feature score for all index fields. Then you can use the following setup of the foreach feature:
Note that you must quote the expression passed in to the rankingExpression feature. |
| dotProduct(name,vector) | 0 |
Note:
Most dot product use cases are better solved using
tensors.
The sparse dot product of the vector represented by the given weighted set attribute and the vector sent down with the query. You can also do an ordinary full dotproduct by using arrays instead of weighted sets. This will be a lot faster when you have full vectors in the document with more than 5-10% non-zero values. You are also then not limited to integer weights. All the numeric datatypes can be used with arrays, so you have full floating point support. The 32 bit floating point type yields the fastest execution.
Each unique string/integer in the weighted set corresponds to a dimension
and the belonging weight is the vector component for that dimension.
The query vector is set in the
rankproperty.dotProduct.vector
query parameter, using syntax
When using an array the dimensions is a positive integer starting at 0. If the query is sparse all non given dimensions are zero. That also goes for dimensions that outside of the array size in each document. Assume a weighted set string attribute X with:
"X": {
"x": 10,
"y": 20
}
for a particular document. The result of using the feature dotProduct(X,Y) with the query vector rankproperty.dotProduct.Y={x:2,y:4} will then be 100 (10*2+20*4) for this document.
Arrays can be passed down as
Note:
When the query vector ends up being the same as the query,
it is better to annotate the query terms with weights
(see term weight)
and use the nativeDotProduct feature instead.
This will run more efficiently and improve the correlation between
results produced by the WAND operator and the final relevance score.
Note:
When using the dotProduct feature,
fast-search is not needed,
unless also used for searching.
When using the dotProduct query operator, use fast-search.
|
| tokenInputIds(length, input_1, input_2, ...) | n/a |
Convenience function for generating token sequence input to Transformer models.
Creates a tensor with dimensions
The inputs are typically retrieved from the query, document attributes or constants.
For instance,
will create a tensor of type |
| customTokenInputIds(start_sequence_id, sep_sequence_idlength, input_1, input_2, ...) | n/a |
Convenience function for generating token sequence input to Transformer models.
Creates a tensor with dimensions
The inputs are typically retrieved from the query, document attributes or constants.
For instance,
|
| tokenTypeIds(length, input_1, input_2, ...) | n/a |
Convenience function for generating token sequence input to Transformer models.
Similar to the |
| tokenAttentionMask(length, input_1, input_2, ...) | n/a |
Convenience function for generating token sequence input to Transformer models.
Similar to the |
Graphs for selected ranking functions
closeness
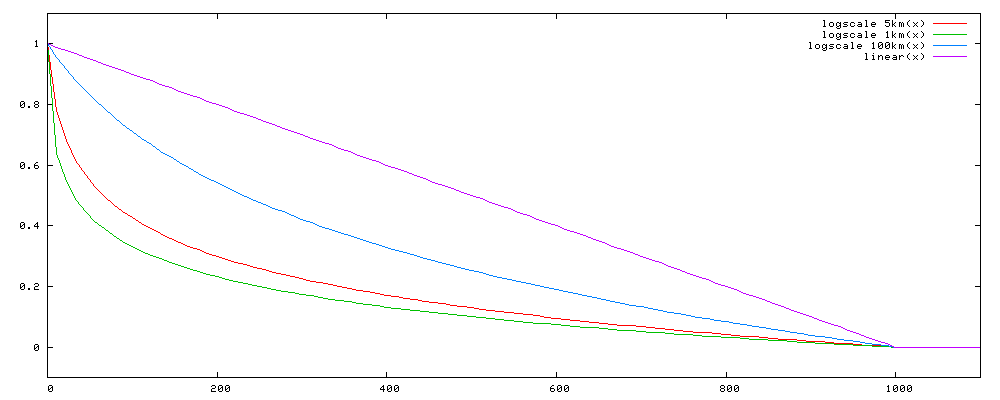
The plot above shows the possible outputs from the closeness distance rank feature using the default maxDistance of 1000 km. The linear(x) graph shows the default closeness output while the other graphs are logscale output for various values of the scaleDistance parameter: 9013.305 (1 km), 45066.525 (5 km - the default value), and 901330.5 (100 km). These values correspond to the following values of the halfResponse parameter: 276154.903 (30.64 km), 593861.739 (65.89 km), and 2088044.581 (231.66 km).
freshness
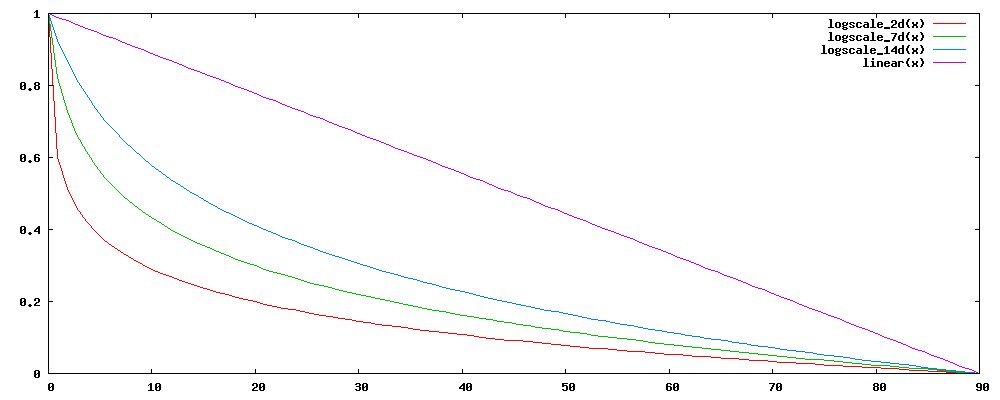
The plot above shows the possible outputs from the freshness rank feature using the default maxAge of 7776000s (90 days). The linear(x) graph shows the default freshness output while the other graphs are logscale output for various values of the halfResponse parameter: 172800s (2 days), 604800s (7 days - the default value), 1209600s (14 days).