In this document we explain various aspects of application deployment in detail.
Refer to application deployment for an introduction.
Convergence
After the deployment command has succeeded, the application package will take effect, but this does
not complete immediately in the distributed system that is your running application;
it happens through a distributed convergence process that you can track from the command line
or console. Refer to the deploy reference
for detailed steps run when deploying an application.
You can get the status of the last deployment by using the status command:
$ vespa status deployment
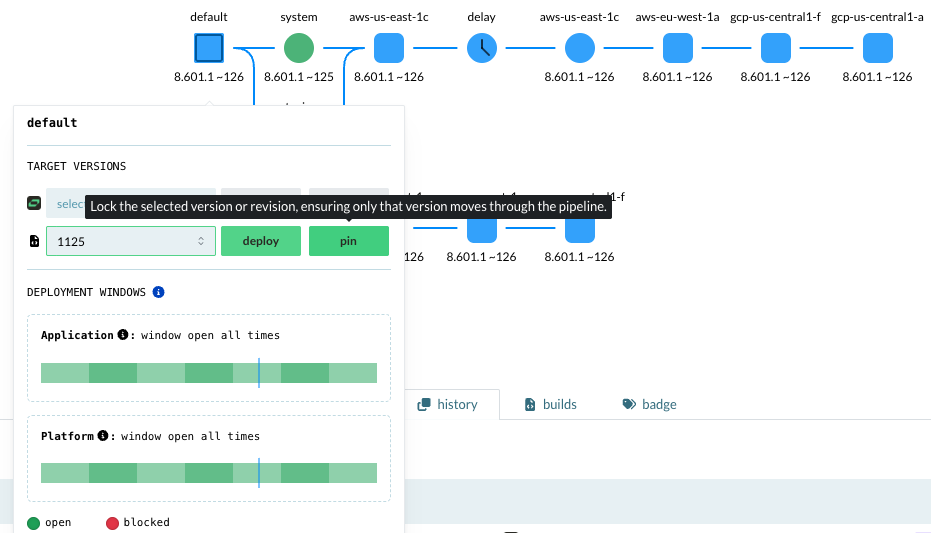
Rollback
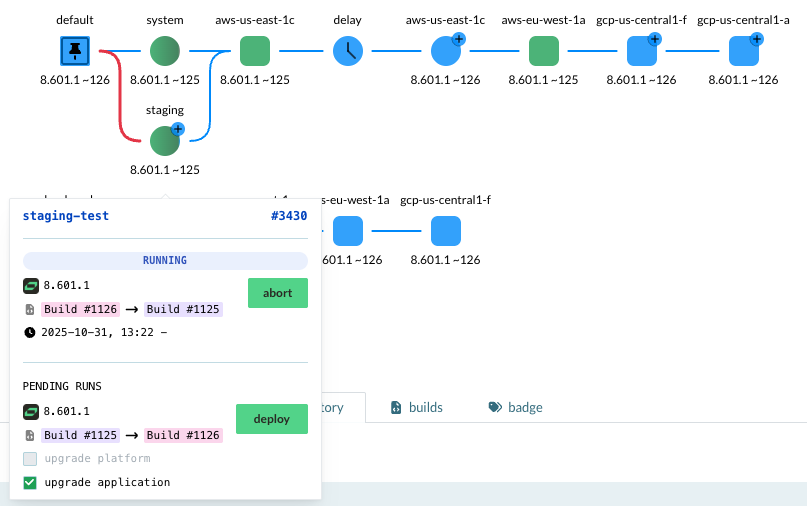
Hover over the instance square to the left, click pin, give a reason -
this will start the downgrade process:
The pinning to a new version starts a new deployment, and can be rolled out as a normal rollout.
To speed it up, cancel system and staging test jobs by clicking abort.
Skipping tests is at the application owners own discretion and risk:
A system test on this version has already been run on an earlier deployment.
Skipping this can be considered safe, for that reason.
A staging test has never been run before when rolling back, this path is untested.
Of the two, the staging test takes longer to run. The user decides whether to skip testing phases or not.
With this, a user can control whether to immediately roll back a version including test phases or not,
as well as rolling out to production zones in parallel or not.
After the pin to rollback, make sure to update the code repository so the next deployments is in sync,
and remove the pin for later deployments.
Follow-up steps
Generally, to roll back an application package change,
deploy again with the previous version to roll back to.
The above section describes the fast-track rollback.
The alternatives are:
With automation: Revert the code in the source code repository, and let the automation roll out the new version.
You can speed up the deployment by skipping tests and clicking "deploy now" in the deployment graph in the console.
If you have trouble rebuilding a good package, you can download a previous package from Vespa Cloud: Use the
console
to pick the good version, download it and deploy again.
Hover of the instance
(normally called "default") to skip the system and staging test to speed up the deployment, if needed.
On self-managed instances, regenerate the good version from source for new deployment,
see also the deploy API
File distribution
The application package can have components and other large files.
When an app is deployed, these files are distributed to the nodes:
When new components or files specified in config are distributed, the container gets a new file reference,
waits for it to be available and switches to new config when all files are available.
Deploying remote models
Most application packages are stored as source code in a code repository.
However, some resources are generated or too large to store in a code repository,
like models or an FSA.
Machine learned models in Vespa,
are stored in the application package under the models directory.
This might be inconvenient for some applications,
for instance for models that are frequently retrained on some remote system.
Also, models might be too large to fit within the constraints of the version control system.
The solution is to download the models from the remote location during the application package build.
This is simply implemented by adding a step in pom.xml
(see example):
Any necessary credentials for authentication and authorization should be added to this script,
as well as any unpacking of archives (for TensorFlow models for instance).
Also see the model config type to specify resources that
should be downloaded by container nodes during convergence.