The Vespa grouping language is a list-processing language
which describes how the query hits should be grouped, aggregated, and presented in result sets.
A grouping statement takes the list of all matches to a query as input and groups/aggregates
it, possibly in multiple nested and parallel ways to produce the output.
This is a logical specification and does not indicate how it is executed,
as instantiating the list of all matches to the query somewhere would be too expensive,
and execution is distributed instead.
Refer to the Query API reference
for how to set the select parameter,
and the Grouping reference for details.
Fields used in grouping must be defined as attribute in the document schema.
Grouping supports continuation objects for pagination.
The operations defining the structure of a grouping are:
all(statement): Execute the nested statement once on the input list as a whole.
each(statement): Execute the nested statement on each element of the input list.
group(specification):
Turn the input list into a list of lists according to the grouping specification.
output: Output some value(s) at the current location in the structure.
The parallel and nested collection of these operations defines both the structure of the computation
and of the result it produces.
For example, all(group(customer) each(output(count())))
will take all matches, group them by customer id, and for each group, output the count of hits in the group.
Vespa distributes and executes the grouping program on content nodes and merges results on container nodes -
in multiple phases, as needed.
As realizing such programs over a distributed data set requires more network round-trips than a regular search query,
these queries may be more expensive than regular queries -
see defaultMaxGroups and the likes
for how to control resource usage.
Grouping by example
For the entirety of this document, assume an index of engine part purchases:
Date
Price
Tax
Item
Customer
Is paid
2006-09-06 09:00:00
$1 000
0.24
Intake valve
Smith
true
2006-09-07 10:00:00
$1 000
0.12
Rocker arm
Smith
false
2006-09-07 11:00:00
$2 000
0.24
Spring
Smith
true
2006-09-08 12:00:00
$3 000
0.12
Valve cover
Jones
false
2006-09-08 10:00:00
$5 000
0.24
Intake port
Jones
true
2006-09-08 11:00:00
$8 000
0.12
Head
Brown
false
2006-09-09 12:00:00
$1 300
0.24
Coolant
Smith
true
2006-09-09 10:00:00
$2 100
0.12
Engine block
Jones
false
2006-09-09 11:00:00
$3 400
0.24
Oil pan
Brown
true
2006-09-09 12:00:00
$5 500
0.12
Oil sump
Smith
false
2006-09-10 10:00:00
$8 900
0.24
Camshaft
Jones
true
2006-09-10 11:00:00
$1 440
0.12
Exhaust valve
Brown
false
2006-09-10 12:00:00
$2 330
0.24
Rocker arm
Brown
true
2006-09-10 10:00:00
$3 770
0.12
Spring
Brown
false
2006-09-10 11:00:00
$6 100
0.24
Spark plug
Smith
true
2006-09-11 12:00:00
$9 870
0.12
Exhaust port
Jones
false
2006-09-11 10:00:00
$1 597
0.24
Piston
Brown
true
2006-09-11 11:00:00
$2 584
0.12
Connection rod
Smith
false
2006-09-11 12:00:00
$4 181
0.24
Rod bearing
Jones
true
2006-09-11 13:00:00
$6 765
0.12
Crankshaft
Jones
false
Basic Grouping
Example: Return the total sum of purchases per customer - steps:
Select all documents:
/search/?yql=select * from sources * where true
Take the list of all hits:
all(...)
Turn it into a list of lists of all hits having the same customer id:
group(customer)
For each of those lists of same-customer hits:
each(...)
Output the sum (an aggregator) of the price over all items in that list of hits:
output(sum(price))
Final query, producing the sum of the price of all purchases for each customer:
/search/?yql=select * from sources * where true limit 0 |
all( group(customer) each(output(sum(price))) )
Here, limit is set to zero to get the grouping output only.
URL encoded equivalent:
Note: in examples above, all documents are evaluated.
Modify the query to add filters (and thus cut latency), like (remember to URL encode):
/search/?yql=select * from sources * where customer contains "smith"
Ordering and Limiting Groups
In many scenarios, a large collection of groups is produced, possibly too large to display or process.
This is handled by ordering groups, then limiting the number of groups to return.
The order clause accepts a list of one or more expressions.
Each of the arguments to order is prefixed by either a plus/minus for ascending/descending order.
Limit the number of groups using max and precision -
the latter is the number of groups returned per content node to be merged to the global result.
Larger document distribution skews hence require a higher precision for accurate results.
An implicit limit can be specified through the
grouping.defaultMaxGroups query parameter.
This value will always be overridden if max is explicitly specified in the query.
Use max(inf) to retrieve all groups when the query parameter is set.
If precision is not specified, it will default to a factor times max.
This factor can be overridden through the
grouping.defaultPrecisionFactor
query parameter.
Example: To find the 2 globally best groups, make an educated guess on how
many samples are needed to fetch from each node in order to get the right groups.
This is the precision.
An initial factor of 3 has proven to be quite good in most use cases.
If however, the data for customer 'Jones' was spread on 3 different content nodes,
'Jones' might be among the 2 best on only one node.
But based on the distribution of the data,
we have concluded by earlier tests that if we fetch 5.67 as many groups as we need to,
we will have a correct answer with at least 99.999% confidence.
So then we just use 6 times as many groups when doing the merge.
However, there is one exception.
Without an order constraint, precision is not required.
Then, local ordering will be the same as global ordering.
Ordering will not change after a merge operation.
Example
Example: The two customers with most purchases, returning the sum for each:
Use summary to print the fields for a hit,
and max to limit the number of hits per group.
An implicit limit can be specified through the
grouping.defaultMaxHits query parameter.
This value will always be overridden if max is explicitly specified in the query.
Use max(inf) to retrieve all hits when the query parameter is set.
Example
Example: Return the three most expensive parts per customer:
/search/?yql=select * from sources * where true |
all(group(customer) each(max(3) each(output(summary()))))
Notes on ordering in the example above:
The order clause is a directive for group ordering, not hit ordering.
Here, there is no order clause on the groups, so default ordering -max(relevance()) is used. The -
denotes the sorting order, - means descending (higher score first).
In this case, the query is "all documents", so all groups are equally relevant and the group order is random.
To order hits inside groups, use ranking. Add ranking=pricerank to the query
to use the pricerank rank profile to rank by price:
Use the filter clause to select which values to keep in a group. See the reference for details.
Examples
Example: Sum the price per customer of Bonn.* where price was over 1000.
/search/?yql=select * from sources * where true |
all(group(customer) filter(regex("Bonn.*", attributes{"sales_rep"}) and not range(0, 1000, price)) each(output(sum(price)) each(output(summary()))))
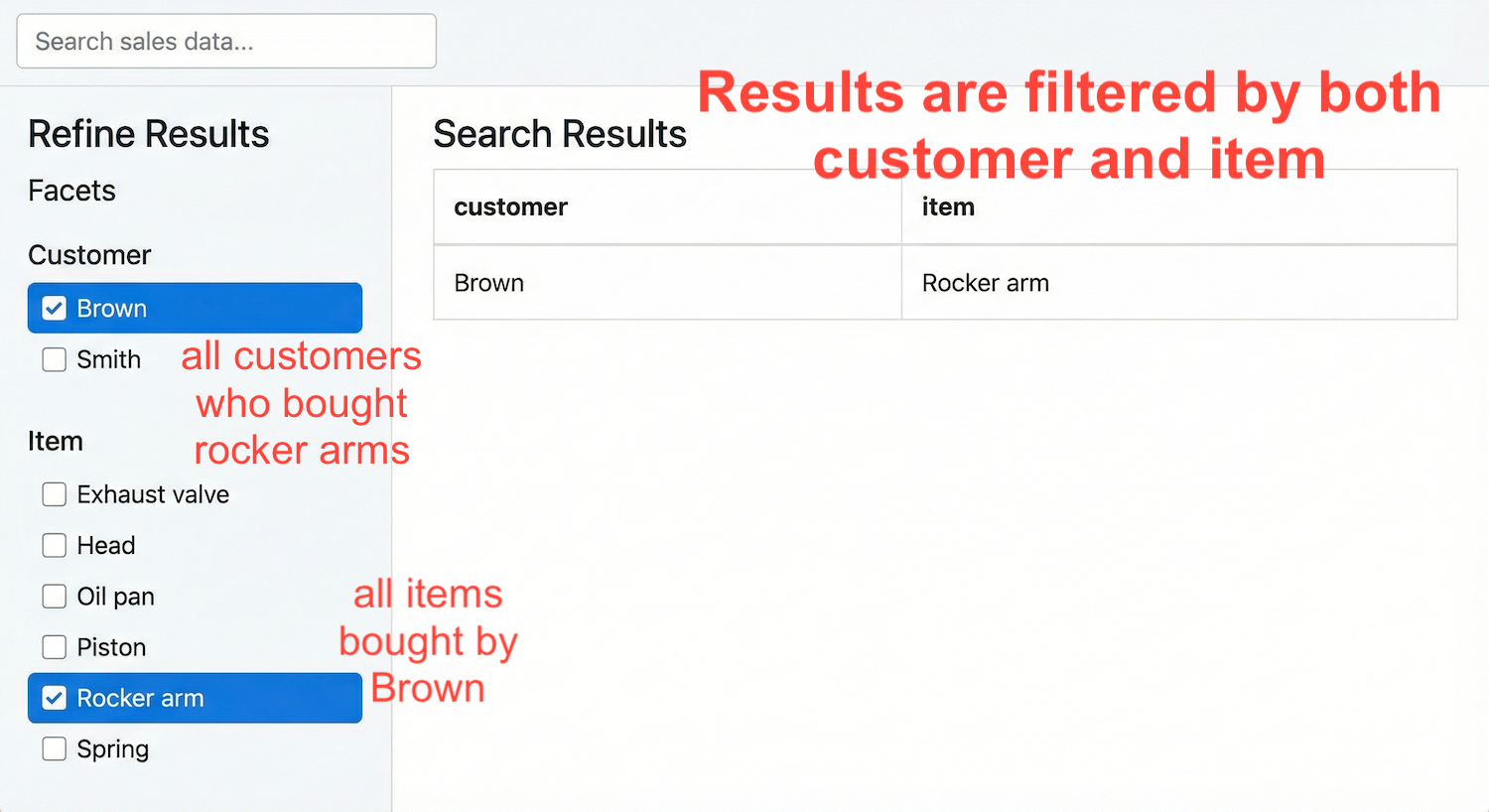
With many faceted search UIs, you often have a filtering problem: if the user clicks on a facet option,
like a customer name, you want to still show all the customers, even though results are filtered by that customer.
Still, if there's another option from another facet (e.g., item name), you want the other facet options,
such as customer names, to only include results matching that item name. In other words, clicking on
a facet option should apply that filter to everything else (other facet options and results list),
but not to itself.
Here's how users expect a UI where they selected both a customer and an item:
To implement this, you need one grouping expression for each filter combination. In this
case, one for the main results list, one for the customer facet, and one for the item facet.
NOTE: using grouping filters for this is a lot slower than running separate
queries and filtering there.
Use istrue to filter using a boolean attribute field directly. For instance, if you want to output how
many purchases have been paid by each customer, you could express that as:
/search/?yql=select * from sources * where true |
all(group(customer) filter(istrue(is_paid)) each(output(count())))
To find out how many purchases have not been paid yet, prepend istrue with not like this:
not istrue(is_paid).
Global limit for grouping queries
Use the grouping.globalMaxGroups query parameter
to restrict execution of queries that are potentially too expensive in terms of compute and bandwidth.
Queries that may return a result exceeding this threshold are failed preemptively.
This limit is compared against the total number of groups and hits that query could return at worst-case.
Examples
The following query may return 5 groups and 0 hits.
It will be rejected when grouping.globalMaxGroups < 5
The grouping.globalMaxGroups restriction will utilize the
grouping.defaultMaxGroups/
grouping.defaultMaxHits
values for grouping statements without a max. The two queries below are identical, assuming
defaultMaxGroups=5 and defaultMaxHits=7, and both will be rejected when
globalMaxGroups < 5+5*7.
A grouping without max combined with defaultMaxGroups=-1/defaultMaxHits=-1
will be rejected unless globalMaxGroups=-1. This is because the query produces an unbounded result,
an infinite number of groups if defaultMaxGroups=-1 or an infinite number of summaries if
defaultMaxHits=-1.
An unintentional DoS (Denial of Service) could be the utter consequence if a query returns thousands of groups and summaries.
This is why setting globalMaxGroups=-1 is risky.
Recommended settings
The best practice is to always specify max in groupings,
making it easy to reason about the worst-case cardinality of the query results. The performance will also benefit.
Set globalMaxGroups to the overall worst-case result cardinality with some margin.
The defaultMaxGroups/defaultMaxHits
should be overridden in a query profile if some groupings do not use max and the default values are too low.
Grouping is, by default, tuned to favor performance over correctness.
Perfect correctness may not be achievable; result of queries using non-default ordering
can be approximate, and correctness can only be partially achieved by a larger precision value that sacrifices performance.
The grouping session cache is enabled by default.
Disabling it will improve correctness, especially for queries using order and max.
The cost of multi-level grouping expressions will increase, though.
Consider increasing the precision value when using max in combination with order.
The default precision may not achieve the required correctness for your use case.
Nested Groups
Groups can be nested. This offers great drilling capabilities,
as there are no limits to nesting depth or presented information on any level.
Example: How much each customer has spent per day by grouping on customer, then date:
Use this to query for all items on a per-customer basis, displaying the most expensive hit for each customer,
with subgroups of purchases on a per-date basis.
Use the summary clause
to show hits inside any group at any nesting level.
Include the sum price for each customer, both as a grand total and broken down on a per-day basis:
/search/?yql=select * from sources * where true limit 0|
all(group(customer)
each(max(1) output(sum(price)) each(output(summary())))
each(group(time.date(date))
each(max(10) output(sum(price)) each(output(summary())))))
&ranking=pricerank
GroupId
sum(price)
Brown
$20 537
Date
Price
Tax
Item
Customer
2006-09-08 11:00
$8 000
0.12
Head
Brown
GroupId
Sum(price)
2006-09-08
$8 000
Date
Price
Tax
Item
Customer
2006-09-08 11:00
$8 000
0.12
Head
Brown
2006-09-09
$3 400
Date
Price
Tax
Item
Customer
2006-09-09 11:00
$3 400
0.12
Oil pan
Brown
2006-09-10
$7 540
Date
Price
Tax
Item
Customer
2006-09-10 10:00
$3 770
0.12
Spring
Brown
2006-09-10 12:00
$2 330
0.24
Rocker arm
Brown
2006-09-10 11:00
$1 440
0.12
Exhaust valve
Brown
2006-09-11
$1 597
Date
Price
Tax
Item
Customer
2006-09-11 10:00
$1 597
0.24
Piston
Brown
Jones
$39 816
Date
Price
Tax
Item
Customer
2006-09-11 12:00
$9 870
0.12
Exhaust port
Jones
GroupId
Sum(price)
2006-09-08
$8 000
Date
Price
Tax
Item
Customer
2006-09-08 10:00
$5 000
0.24
Intake port
Jones
2006-09-08 12:00
$3 000
0.12
Valve cover
Jones
2006-09-09
$2 100
Date
Price
Tax
Item
Customer
2006-09-09 10:00
$2 100
0,12
Engine block
Jones
2006-09-10
$8 900
Date
Price
Tax
Item
Customer
2006-09-10 10:00
$8 900
0.24
Camshaft
Jones
2006-09-11
$20 816
Date
Price
Tax
Item
Customer
2006-09-11 12:00
$9 870
0.12
Exhaust port
Jones
2006-09-11 13:00
$6 765
0.12
Crankshaft
Jones
2006-09-11 12:00
$4 181
0.24
Rod bearing
Jones
Smith
$19 484
Date
Price
Tax
Item
Customer
2006-09-10 11:00
$6 100
0.24
Spark plug
Smith
GroupId
Sum(price)
2006-09-06
$1 000
Date
Price
Tax
Item
Customer
2006-09-06 09:00
$1 000
0.24
Intake valve
Smith
2006-09-07
$3 000
Date
Price
Tax
Item
Customer
2006-09-07 11:00
$2 000
0.24
Spring
Smith
2006-09-07 10:00
$1 000
0.12
Rocker arm
Smith
2006-09-09
$6 800
Date
Price
Tax
Item
Customer
2006-09-09 12:00
$5 500
0.12
Oil sump
Smith
2006-09-09 12:00
$1 300
0.24
Coolant
Smith
2006-09-10
$6 100
Date
Price
Tax
Item
Customer
2006-09-10 11:00
$6 100
0.24
Spark plug
Smith
2006-09-11
$2 584
Date
Price
Tax
Item
Customer
2006-09-11 11:00
$2 584
0.12
Connection rod
Smith
Structured grouping
Structured grouping is nested grouping over an array of structs or maps.
In this case, each array element is treated as a sub-document and may
be grouped separately. See the reference for grouping on
multivalue attributes
for details. It is also possible to
filter the groups
so only matching elements are considered. An example could be:
This gives one group per price. To group on price ranges, one could compress the price range.
This gives prices in $0 - $999 in bucket 0, $1 000 - $2 000 in bucket 1 and so on:
Grouping supports continuation objects
that are passed as annotations to the grouping statement.
The continuations annotation is a list of zero or more continuation strings,
returned in the grouping result.
For example, given the result:
The continuations annotation is an ordered list of continuation strings.
These are combined by replacement
so that a continuation given later will replace any shared state with a continuation given before.
Also, when using the continuations annotation,
always pass the this-continuation as its first element.
Note:
Continuations work best when the ordering of hits is stable -
which can be achieved by using ranking or
ordering.
Adding a tie-breaker might be needed - like random.match
or a random double value stored in each document -
to keep the ordering stable in case of multiple documents that would otherwise get the same rank score
or the same value used for ordering.
Expressions
Instead of just grouping on some attribute value,
the group clause may contain arbitrarily complex expressions -
see group in the
grouping reference for an exhaustive list.
Examples:
Select everything. For example, group("all") each(output(sum(price))) gives total revenue
Select the minimum or maximum of sub-expressions
Addition, subtraction, multiplication, division, and even modulo of sub-expressions
Bitwise operations on sub-expressions
Concatenation of the results of sub-expressions
Sum the prices of purchases on a per-hour-of-day basis:
These types of expressions may also be used inside output operations,
so instead of simply calculating the sum price of the grouped purchases,
calculate the sum income after taxes per customer:
Note that the validity of an expression depends on the current nesting level.
For, while sum(price) would be a valid expression for a group of hits, price would not.
As a general rule, each operator within an expression either applies to a single hit or aggregates values across a group.
Search Container API
As an alternative to a textual representation,
one can use the programmatic API to execute grouping requests.
This allows multiple grouping requests to run in parallel,
and does not collide with the yql parameter - example:
@OverridepublicResultsearch(Queryquery,Executionexecution){// Create grouping request.GroupingRequestrequest=GroupingRequest.newInstance(query);request.setRootOperation(newAllOperation().setGroupBy(newAttributeValue("foo")).addChild(newEachOperation().addOutput(newCountAggregator().setLabel("count"))));// Perform grouping request.Resultresult=execution.search(query);// Process grouping result.Grouproot=request.getResultGroup(result);GroupListfoo=root.getGroupList("foo");for(Hithit:foo){Groupgroup=(Group)hit;Longcount=(Long)group.getField("count");// TODO: Process group and count.}// Pass results back to calling searcher.returnresult;}
The timezone query parameter can be used to rewrite each time-function with a timezone offset.
See the reference. Example:
$ vespa query "select * from purchase where true | \
all( group(time.hourofday(date)) each(output(count()))" \
"timezone=America/Los_Angeles"
This query selects all documents from purchase, groups them by the
hour they were made (adjusted to the local time
in America/Los_Angeles), and counts how many purchases fall into
each hour.
Geo distance
Use geo_distance to compute the great-circle distance from a
position field to a given point.
Append .km or .miles to select the output unit.
The function works on both position and array<position> fields.
For arrays, the minimum distance is returned.
See the reference.
Group into 100 km distance buckets from a point:
select * from purchase where true limit 0 |
all( group(fixedwidth(geo_distance(attribute(location), 63.4, 10.4).km, 100.0)) each(output(count())) )
Output the minimum and maximum distance per customer:
select * from purchase where true limit 0 |
all( group(customer) each(output(min(geo_distance(attribute(location), 63.4, 10.4).km),
max(geo_distance(attribute(location), 63.4, 10.4).km))) )
Counting unique groups
The count aggregator can be applied on a list of groups to determine the number of unique groups
without having to explicitly retrieve all groups.
Note that this count is an estimate using HyperLogLog++ which is an algorithm for the count-distinct problem.
To get an accurate count, one needs to explicitly retrieve all groups
and count them in a custom component or in the middle tier calling out to Vespa.
This is network intensive and might not be feasible in cases with many unique groups.
Another use case for this aggregator is counting the number of unique instances matching a given expression.
Output an estimate of the number of groups, which is equivalent to the number of unique values for attribute "customer":
select * from purchase where true limit 0 | all( group(customer) each(output(count())) )
Output an estimate of the number of unique string lengths for the attribute "item":
select * from purchase where true limit 0 | all(group(strlen(item)) each(output(count())))
Output the sum of the "price" attribute for each group
in addition to the accurate count of the overall number of unique groups
as the inner each causes all groups to be returned.
select * from purchase where true limit 0 | all(group(customer) output(count()) each(output(sum(price))))
The max clause is used to restrict the number of groups returned.
The query outputs the sum for the 3 best groups.
The count clause outputs the estimated number of groups (potentially >3).
The count becomes an estimate here as the number of groups is limited by max,
while in the above example, it's not limited by max:
select * from purchase where true limit 0 | all(group(customer) max(3) output(count()) each(output(sum(price))))
Output the number of top-level groups, and for the 10 best groups,
output the number of unique values for attribute "item":
select * from purchase where true limit 0 | all(group(customer) max(10) output(count()) each(group(item) output(count())))
Counting unique groups - multivalue fields
A multivalue attribute is a
weighted set,
array or
map.
Most grouping functions will just handle the elements of multivalued attributes separately,
as if they were all individual values in separate documents.
If you are grouping over array of struct or maps, scoping will be used to preserve structure.
Each entry in the array/map will be treated as a separate sub-document,
so documents can be counted twice or more - see
#33646 for details.
This could be solved by adding an additional level of grouping,
where you group on a field that is unique for each document (grouping on document ID is not supported).
You may then count the unique groups to determine the unique document count:
select * from purchase where true limit 0 | all(group(customer) each(group(item) output(count())))
Impression forecasting
Using impression logs for a given user,
one can make a function that maps from rank score to the number of impressions an advertisement would get - example:
Storing just the first column (the rank scores, including a rank score for 0 impressions)
in an array attribute named impressions, the grouping operation
interpolatedlookup(impressions, relevance())
can be used to figure out how many times a given advertisement would have been shown to this particular user.
So if the rank score is 0.420 for a specific user/ad/bid combination,
then interpolatedlookup(impressions, relevance()) would return 5.0.
If the bid is increased so the rank score gets to 0.490,
it would get 5.5 as the return value instead.
In this context, a count of 5.5 isn't meaningful for the past of a single user,
but it gives more information that may be used as a forecast.
Summing this across more, different users may then be used to forecast
the total of future impressions for the advertisement.
Aggregating over all documents
Grouping is useful for analyzing data.
To aggregate over the full document set, create one group (which will have all documents)
by using a constant (here 1) - example:
select rating from restaurant where true | all(group(1) each(output(avg(price))))
Make sure all documents have a value for the given field, if not, NaN is used, and the final result is also NaN:
Count number of documents missing a value for an attribute field
(actually, in this example, unset or less than 0, see the bucket expression below).
Set a higher query timeout, just in case.
Example, analyzing a field called price:
select rating from restaurant where true | all( group(predefined(price, bucket[-inf, 0>, bucket[0, inf>)) each(output(count())) )
Example output, counting 2 documents with -inf in rating: