-
Applications and components
- Developer guide
- IDE support
- Deployment
- .vespaignore files
- Containers
- Components
- Searchers
- Document processors
- Request handlers
- Result renderers
- Dependency injection
- Configuring components
- Chaining
- Inspecting structured data in a Searcher
- Developing web services
- Unit testing
- System testing
- The config system
- Request-response processing
- Bundles
- Using ZooKeeper
- Http servers and filters
- Using pluggable frameworks
- Java config API
-
Querying
- The query api
- The YQL query language
- Grouping and aggregation
- Federation
- Query profiles
- An intro to vector search
- Nearest neighbor search
- Approximate nearest neighbor search
- Nearest neighbor search guide
- Text matching
- Searching multivalue fields
- Geo search
- Document summaries
- Result diversity
- Page templates
-
Ranking and inference
- Ranking introduction
- Ranking expressions and features
- Multivalue query operators
- Tensor user guide
- Tensor examples
- Phased ranking
- Using TensorFlow models
- Using ONNX models
- Using XGBoost models
- Using LightGBM models
- Wand: Accelerated OR search
- The BM25 rank feature
- The nativeRank rank feature
- Cross-encoder transformer ranking
- Searcher re-ranking
- Significance model
- Stateless model evaluation
-
Linguistics and text processing
-
Content and elasticity
-
Performance
- Performance overview
- Practical performance guide
- Serving sizing guide
- Feed sizing guide
- Node resources
-
Instance types
- Topology and resizing
- Streaming search
- Benchmarking
- Benchmarking using Vespa Cloud
- Memory visualizer
- Profiling
- Container tuning
- Rate-limiting queries
- Graceful degradation
- Caches
- HTTP performance testing
- HTTP/2
- Feature tuning
- Valgrind
-
Operations
- Quota
- Environments
- Zones
- Availability Zones
- Production deployment
- Deployment variants
- Automated deployments
- Autoscaling
-
Enclave: Bring your own cloud
- Reindexing
- Reindexing on Vespa Cloud
- Data management and backup
- Cloning applications and data
- Monitoring
- Metrics
- Telemetry export
- Notifications
- Support
- Login Help
- Single Sign-On (SSO) Setup
- Deployment patterns
- Private endpoints
- Endpoint routing
- Access logging
-
Artifact archive
- Deleting applications
-
Self-managed
- Admin procedures
- Multinode Systems
- Files, Processes, Ports, Environment
- Node Setup
- Using Kubernetes
- Build and install
- Monitoring
- Content node recovery
- Configuration Servers
- Live Vespa upgrade procedure
- Config Sentinel
- Config Proxy
- Docker Containers
- Docker Containers GPU setup
- CPU Support
- Service Location Broker
- Change from attribute to index procedure
- Container
- Sizing examples
- Vespa Support CLI
-
Kubernetes
-
Modules
-
Reference
-
Applications and components
-
Schemas and documents
-
Reading and writing
-
Operations
- Health checks
- Log files
- Tools
-
Self-managed
-
Security
-
Release notes
Vector Search is a method to search objects using a digital representation of both the query and the objects - easier explained by example:
Consider a user searching for the flower "Dandelion". A regular text search will match this Wikipedia article, as the "dandelion" term is in the text:
Taraxacum
From Wikipedia, the free encyclopedia (Redirected from Dandelion)
"Dandelion" redirects here. It may refer to any species of the genus Taraxacum or specifically to Taraxacum officinale. For similar plants, see False dandelion. For other uses, see Dandelion (disambiguation)
Taraxacum (/təˈræksəkʊm/) is a large genus of flowering plants in the family Asteraceae, which consists of species commonly known as dandelions.
...
This document is about dandelions, for sure. However, if the user searches for "blowball" (the mature spherical seed head of a dandelion), the text above will not match, although the document is a good match for "blowball". Example images of a dandelion:


Photos by Greg Hume
This gets more complicated with more content types. It is hard to use text search to match the images without any text. The same goes for videos, podcasts, songs, TV shows, and so on - this is often called multi-modal search. A workaround is to search the object’s textual metadata, like a song’s title, the podcast episode summary, and the image’s alt text on the webpage. Such metadata is only sometimes available and is often too short/imprecise - this does not solve the root problem.
The query can be an image itself or a song, where the users want more like this, in the context of the current song or an image being viewed. This is a problem found in recommender systems.
Digital representations
A solution to the synonym or multi-modal problem is to change from matching in the textual to the digital domain. This means transforming text, images, and songs into a set of numbers that indicate what it is about.
Examples of different objects, and their vector representation:
| [0.560, 0.001, 0.223, ...] | |
 |
[0.0, 0.011, 0.0, ...] |
| "Taraxacum is a large genus of flowering plants in the family Asteraceae, which consists of species commonly known as dandelions." | [0.002, 0.001, 0.411, ...] |
| dandelions | [0.002, 0.021, 0.355, ...] |
The digital representation of the object is hence a sequence of numbers, called a vector, also called an embedding.
By converting all the objects searched for and the query to vectors (digital representations), the search problem is changed into finding similar vectors - i.e., vector search.
How vectors are created
Creating vectors from the objects can be done in multiple ways. Machine learning is often used; there are many ready-made models to get you started.
The quality of the vectors will decide the quality of the search, so this is where organizations will want to spend their effort improving search.
A vector has a dimension (length) and type (type of each cell).
The cost/quality tradeoff is essential - given a vector, it can be represented with lower precision or shortened, keeping the most relevant dimensions. This reduces search precision, but cuts costs into a fraction. A 75% cost reduction might reduce precision, but acceptable for the use case. Vespa supports four types, with an 8x difference in memory cost:
| Int8 | 8 bits, 1 byte per dimension |
|---|---|
| bfloat16 | 16 bits, 2 bytes per dimension |
| float | 32 bits, 4 bytes per dimension |
| double | 64 bits, 8 bytes per dimension |
Read more on selecting the optimal type:
Vectors are often some hundred numbers long, like 768 or 384. A longer vector can hold more information, but some dimensions are more information-rich than others. If most of the values in a dimension are equal or very close to each other, the dimension has little value and can be eliminated:
A better approach is often to use an ML model with the optimal size from the start for the use case, once found.
Doing a vector search
"dandelion" matches "dandelion", but "rose" does not. Text search has a binary nature. However, both are flowers and considered more similar to each other than "airplane". Unlike text matching, a vector search will not match items exactly. In the following example, we are using a very short 3-dim vector for simplicity and using the dimensions as coordinates in a 3D space:
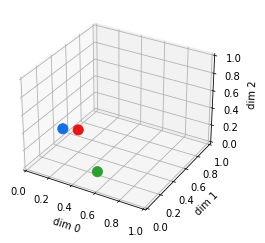
We see that [0.000, 0.497, 0.110] is not equal to [0.101, 0.560, 0.093], but quite close - closer than [0.611, 0.000, 0.217].
In other words, if the values for each dimension are close, the vectors are similar - and this can be used in search to find the nearest neighbor or NN. There are multiple ways to calculate vector similarity using a distance metric:
Approximate for speed
Calculating vector similarity can be thought of as multiplying the number of dimensions with the number of vectors. If you are a Canadian, represented by a 768-dim vector, this is 768 x 39,000,000 = 29,952,000,000, or 29 billion calculations to find the other Canadian most similar to you.
There are ways to approximate this by doing fewer calculations, and still finding the closest vector with high probability - this is called Approximate Nearest Neighbor search, or ANN search. Vespa supports both exact nearest neighbor search and ANN search:
Note that ANNs require some kind of indexing to speed up search, so inserts (adding a new vector) are more expensive (uses more CPU) and takes more space (memory and disk). When evaluating different kinds of ANN indexing, consider if your use case requires updates, including deletes, to the vectors - Vespa supports all.